
联系我们
如您对参会报名、网站使用、内容发布有任何疑问或改进意见,请随时与我们进行沟通!
客服企业微信

期待您的宝贵意见
袁先智 数联铭品科技有限公司(BBD)高级副总裁兼首席风险官
本报告的目的是分享以大数据分析为基础的金融科技创新与实践。基于人工智能算法针对刻画企业财务欺诈风险特征的筛选框架的建立和应用。同时,结合一系列最新事件我们会进行真实场景的讨论。我们要把企业欺诈的事情搞清楚。
从金融科技的大数据思维出发,结合人工智能 (AI) 中的吉布斯抽样 (Gibbs Sampling)算法,我们分享如何建立针对刻画企业财务欺诈风险特征的筛选框架。作为应用,我们将分享:
1. 结合从2019年下半年发生的事件,分享基于上市公司财务欺诈,违约倒闭,和公司财务质量问题引发的信用风险案例。
2. 如何支持基于国内八千多家企业/公司进行主体信用评级体系的情况,陈述我们 CAFÉ(咖啡馆)评估体系的表现情况。
2002年标准SAS No.99中对财务欺诈需要考虑的范围包括压力、机会、借口三个维度。其中压力涵盖金融稳定性或盈利能力,受到经济、行业或者实际经营状况的影响;为满足第三方要求,管理层面临较大压力;管理层或董事由于个人财务状况发生的行为;为了达到董事或管理层设定的财务目标,管理层或公司经营人员承受了过大的压力。机会就是环境。借口就是寻找相应的理论,比如说我们说的财务盈利管理,若稍微说的过分了,其实就是一种作假。
非结构化特征的提取首要问题是解决坏样本不够的问题,我们通过AI手段实现。从79年到现在,公司违约倒闭的不超过220家,每年10家。2016年到2019年,国家监管很规范,提出了多种要求,我们主要是2016年1月到2019年9月,把所有能够从非结构化文本角度解读的数据总结起来,我们称为最原始的黑样本,有2700多个。
吉布斯采样(英语:Gibbs sampling)是统计学中用于马尔科夫蒙特卡洛(MCMC)的一种算法,用于在难以直接采样时从某一多变量概率分布中近似抽取样本序列。该序列可用于近似联合分布、部分变量的边缘分布或计算积分(如某一变量的期望值)。某些变量可能为已知变量,故对这些变量并不需要采样。
吉布斯采样常用于统计推断(尤其是贝叶斯推断)之中。这是一种随机化算法,与最大期望算法等统计推断中的确定性算法相区别。
与其他MCMC算法一样,吉布斯采样从马尔科夫链中抽取样本,可以看作是Metropolis– Hastings算法的特例。该算法的名称源于约西亚•威拉德•吉布斯,由斯图尔特•杰曼与唐纳德 •杰曼兄弟于1984年提出。
它的好处就在于不假设前面有分布。还有其他的很多统计学的算法,但是吉布斯抽样,是被叫做MH的一个算法,我们不知道非结构化数据的分布形式怎么样。
使用此方法要注意两点,第一,我们在理想上要求有无穷多的坏样本的样本来得出特征结论。但若没有这么多坏样本怎么办?就用足够有限的部分样本,每一个样本中有一个OR值,反推无穷大的样本中,通过aic或者bic的一个标准保证这个样本在标准误差比较两倍的标准误差小于5%。非结构化推断特征推断的时候,传统的统计学的方法用不上,很多国内外的文章用统计学的方法把非结构化的变量当成一个因子放在统计学里面。用统计学的方法会丢掉很多信息。
AIC(赤池)信息量准则(英语:Akaike information criterion,简称AIC)是评估统计模型的复杂度和衡量统计模型“拟合”资料之优良性(英语:Goodness of Fit,白话:合身的程度)的一种标准,是由日本统计学家赤池弘次创立和发展的。赤池信息量准则建立在信息熵的概念基础上。
BIC:Bayesian information criterion,贝叶斯信息度量,也叫 SIC, SBC, SC,SBIC。
AIC:基于Kullback-Leibler (K-L)信息损失的,provides an asymptotically unbiased estimator of the expected Kullback discrepancy between the generating model and the fitted approximating model[ 1 ] BIC:基于贝叶斯因子。
AIC,BIC比较 AIC和BIC的公式中前半部分是一样的,后半部分是惩罚项,当n ≥ 8, kln(n)≥2k 所以,BIC相比AIC在大数据量时对模型参数惩罚得更多,导致BIC更倾向于选择参数少的简单模型。

aic和bic不一样的地方,aic是什么东西?如果你选择模型希望参数多一点,那么就用aic,如果模型样本比较大,想参数比较有显著性,不要这么多,那么就用bic。
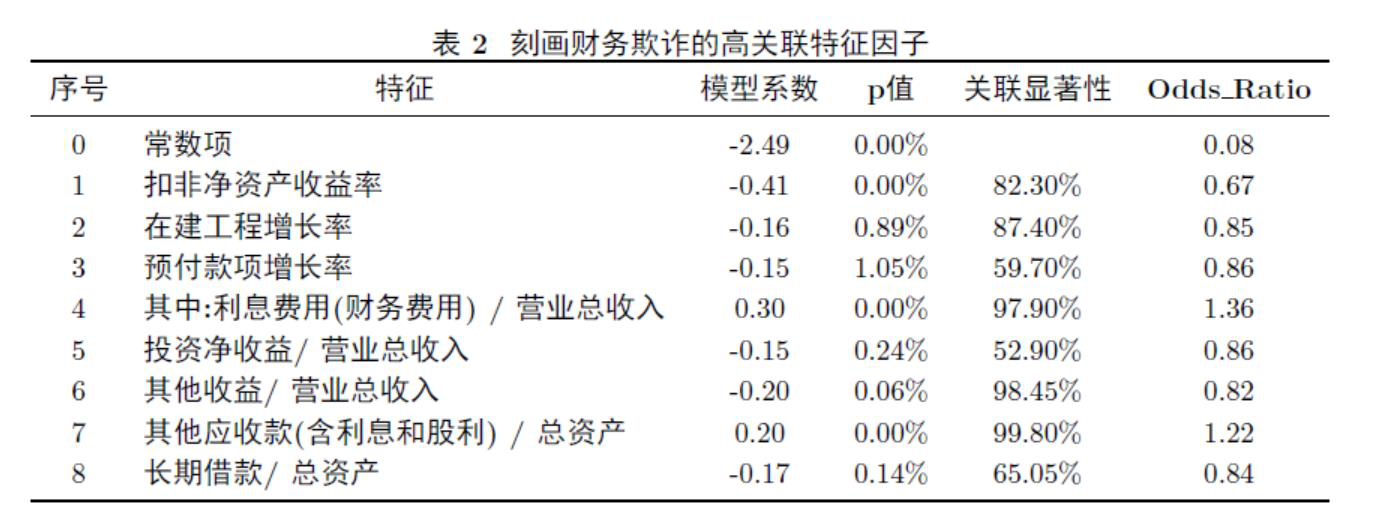
有了2700个真实发生坏样本的事件,第一可以建模型,建立模型中很重要的一步叫做中间变量,我现在找出来的No.1-No.8,就是8个可以刻画欺诈的特征。我们这8个指标又有183个小指标。不管是结构化还是非结构化,要扔到池子里面让数据游一圈。或者说到景德镇里面池子里面去烧一下。烧出来后判定哪些是我需要的特征。现在我们摸出一个套路来做这个事情。
第一,我假设有5%,吉布斯抽样让我做随机抽样,随机抽样里面就有一个样本上最基本的概念,不管你是结构化还是非结构化,样本量越多越好,但在实际中不可能。那么我就用两倍的标准方差小于5%,得出这样做400次的随机抽样计算就够了。这非常重要,我如果容忍我的样本的误差5%,可称为可靠的高度关联。
第二,用odds ratios来分类有关的东西,这里面因为是高度关联或者值大于等于1.2,小于等于0.8。一般关联是大于等于1.1,小于等于0.9,我们叫做一般关联。如果是在0.9~1.1之间,我们叫低度关联,你会发现我们的8个维度都是属于高度关联,我就从这个角度来讲,可以高度解释,中度解释和低度解释,也就完成了对没有统计学推断理论的非结构化特征提取的一个推断和解读。


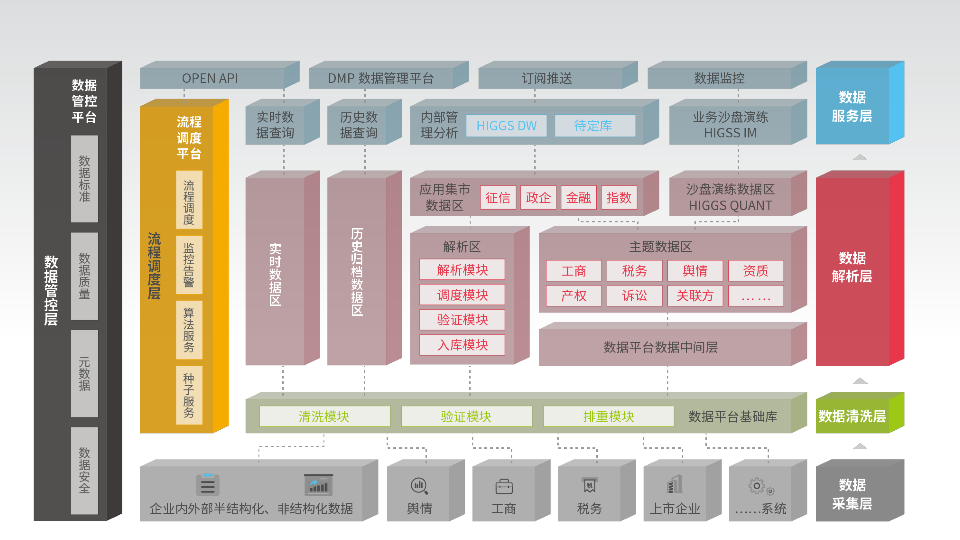
针对 “(财务)欺诈”进行甄别和预防的预警解决方案,至少从下面三给维度进行分析和处理:
I: 从公司本身的财务指标(公司的商务运营)
II: 从公司的董监高(公司的治理框架)
III: 从支持日程管理的内外审计管理和执行功能
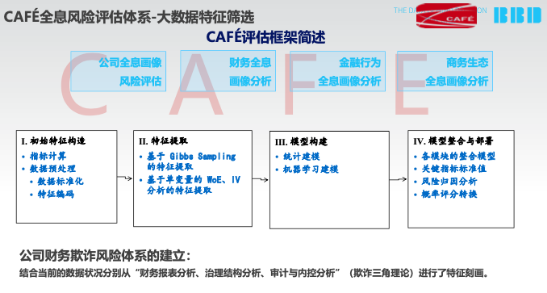
我们结合过去10年,中国差不多有8大类的舞弊公司作为我们真实的坏样本,请注意这个时候的坏样本是用我们前面得出的的8个指标的样本。
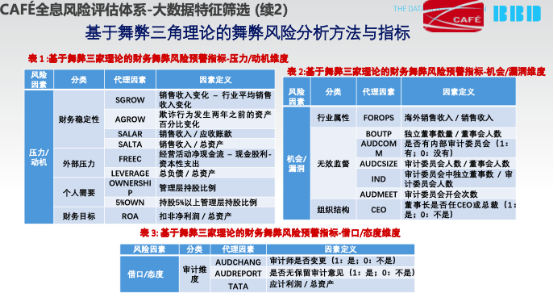
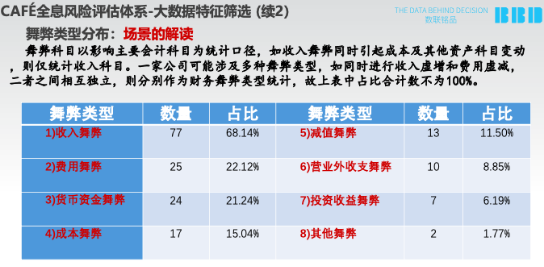
我们基于2700个样本,以及对真实的100多个作假案例,计算它的8个指标,有显著的不一样。这是ROC的显著,这是0.67~0.7左右的特征。
要解读完善的治理框架,就是董事会、监事会和完整的内部的审计部门。要将其细化,细化为是什么执行职责,有什么工作类型,还有高管占股的比例。从大股东到董监高,再到中层管理层来分析。我们得出一个结论,下图中红色是高度关联且有敏感性的,这是一个区间的概念,不是某一个点。
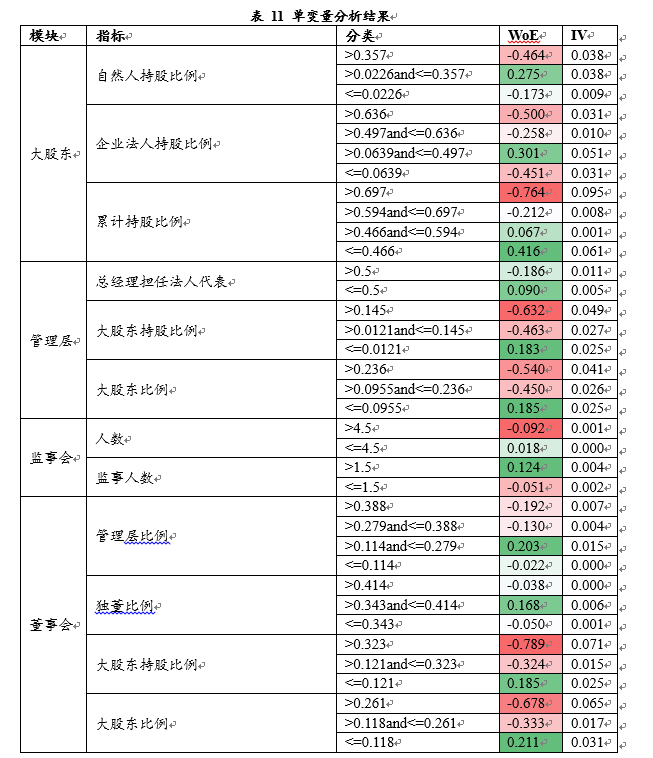
有了这个指标后,通过测试,我们认为:股权结构是影响公司财务欺诈风险的最重要的原因:
1、变量1说明大股东当中如果法人合计持股大于5%但又低于50%时,财务欺诈风险下降;
2、变量2说明股权结构集中有利于降低财务欺诈风险,十大股东(或所有持股5%以上的股东)合计持股比例低于60%时财务欺诈风险上升;
3、变量3说明管理层持股的安排同样有利于降低财务欺诈风险;
4、变量4说明董事会中应留有大股东的席位。
模型比较简洁,但仍能从公司治理的角度对于公司的财务欺诈风险进行刻画,使用ROC对模型进行检验可见:模型在样本内外的AUC值分别为0.630和0.649,说明模型能部分刻画财务欺诈风险。
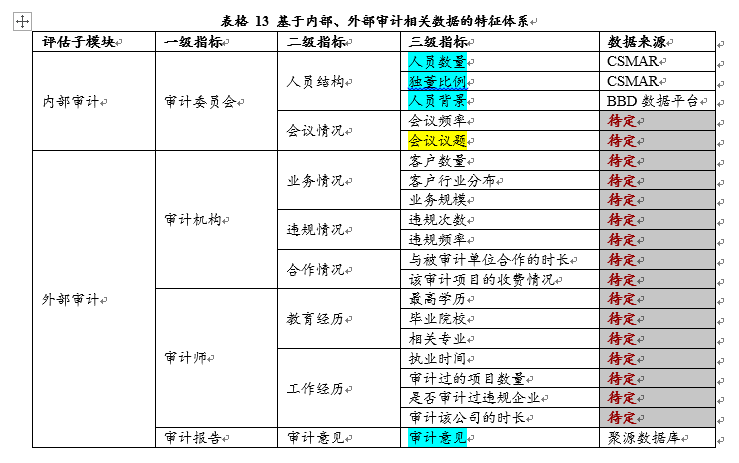
遗憾的是内外审计的治理框架和整个运营效率中的许多数据通常是不可得的。如果做一个很好的审计,可以发现作假,但外部审计和内部审计的数据非常有限。如果我得到从开会的频率和会议的议题,到下面审计意见,差不多15个左右的指标全部有,我可以比较自信的指出哪家公司做欺诈或没欺诈,但是在实践中不管东方、西方还是中国和美国、欧洲,这部分的数据一般拿不到,所以说欺诈公司的欺诈永远存在。
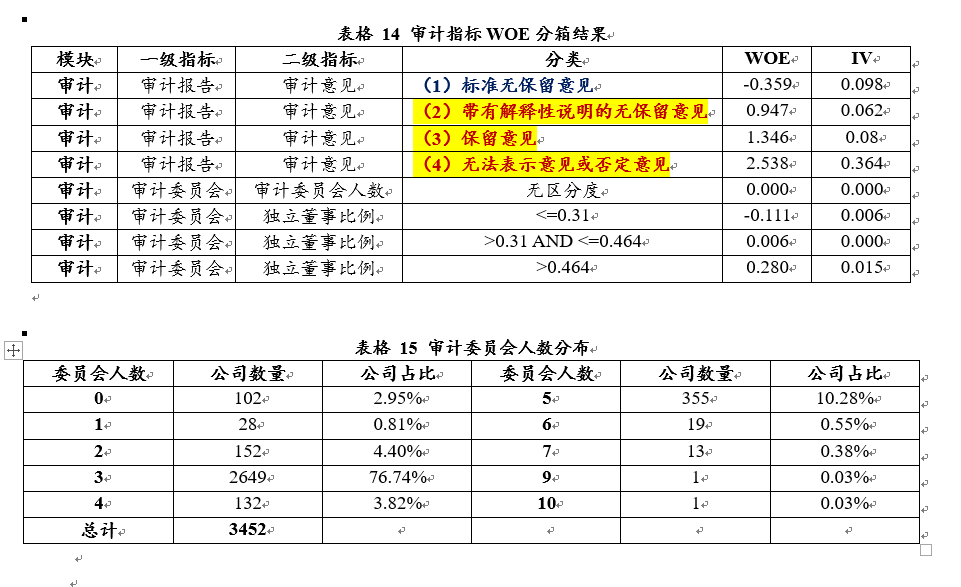
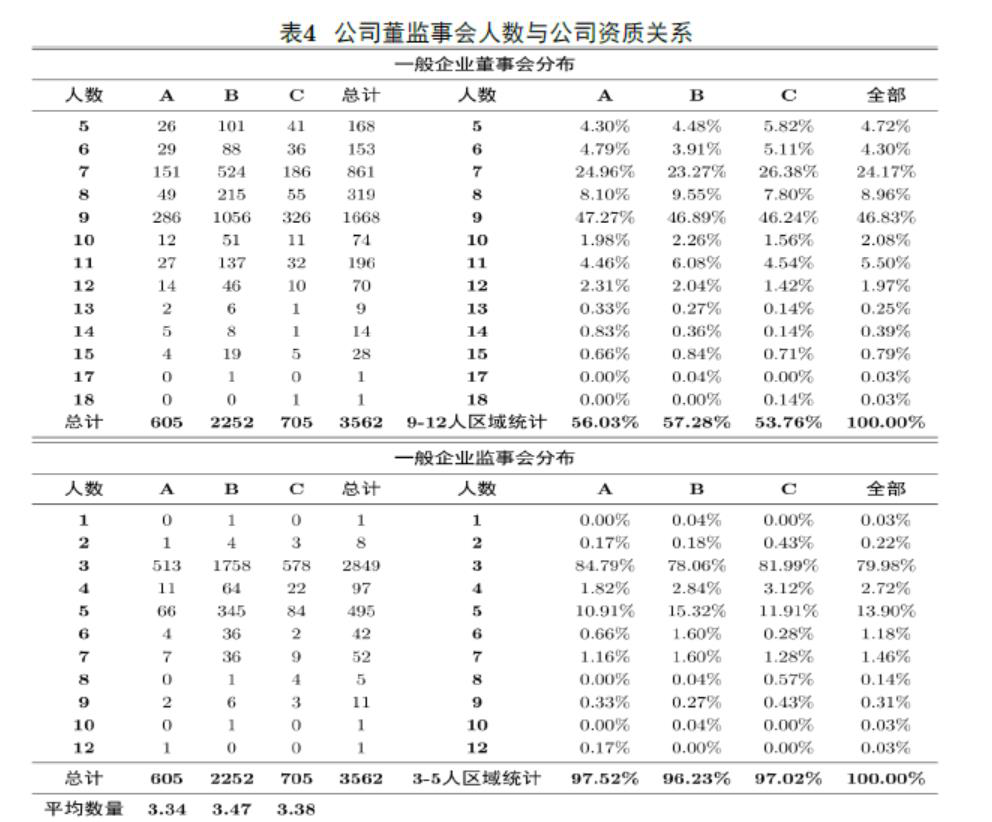
公司审计委员会成员到底对公司做欺诈有没有影响?我们发现即使有完善的治理框架也并不能保证它就是好的公司。一般公司董事会有7个或者9个成员,这是标准化的,中国的注册公司有此需要,西方也是,但金融机构可能是20多个人,是一个庞大的体系。最后大家会发现公司的好坏和董事会有没有完善的治理框架没有关系。
用我们前面讲的财务的标准和刚才讲的治理框架中间的5大标准,来分析两件事情。广州浪奇公司事件是10月份很大做假事件,公司有100亿存款,为什么10亿都还不起呢?在这8大指标中,用全息画像,拉出三年指标,我们会发现此公司远离中位数。而且反欺诈的4个指标中,此公司所在的区间就在我们所谓的要引发欺诈的区间。大股东占股比例0.45;大股东累积持股比例0.49;管理层持股0;董事会大股东的比例也是0。说明我们的指标是很有效的预警指标。
另外是永城煤矿集团,市场称之为恶意违约,但是我对永城恶意违约持有保留意见,将其全息画像调入咖啡馆体系,会发现煤电控股集团中,此集团债券属于高风险债券。如果社会知道这个公司的主体或者债券,根本没有资格获得3B评级,就不会引起说大家说的违约。问题主要在于其国资背景,同时其状况确实不好。所以这不是恶意违约,就是违约。
大家都知道茅台酒厂好,但茅台酒厂在我们的评级里面,永远不是3A。我们发现茅台是唯一一个在中华人民共和国土地里面没有应收账款的公司,我不是对茅台酒厂本身有什么意见,但我一直认为茅台酒厂这方面是有问题的,这个可能也是跟欺诈有关联的。
来源:2020(第十六届)中国金融风险经理年度总论坛




