
联系我们
如您对参会报名、网站使用、内容发布有任何疑问或改进意见,请随时与我们进行沟通!
客服企业微信

期待您的宝贵意见
孙宇熙 Ultipa Graph创始人&CEO
今天的主题从简单地介绍银行卡诈骗风险开始。
银行卡的欺诈风险,比较常见的趋势是从个案、个例走向专业化、团伙化、国际化。所谓团伙化,如果用数学的语言,图论的语言来看,其实是侧重于数据之间高度的关联性、网络性。
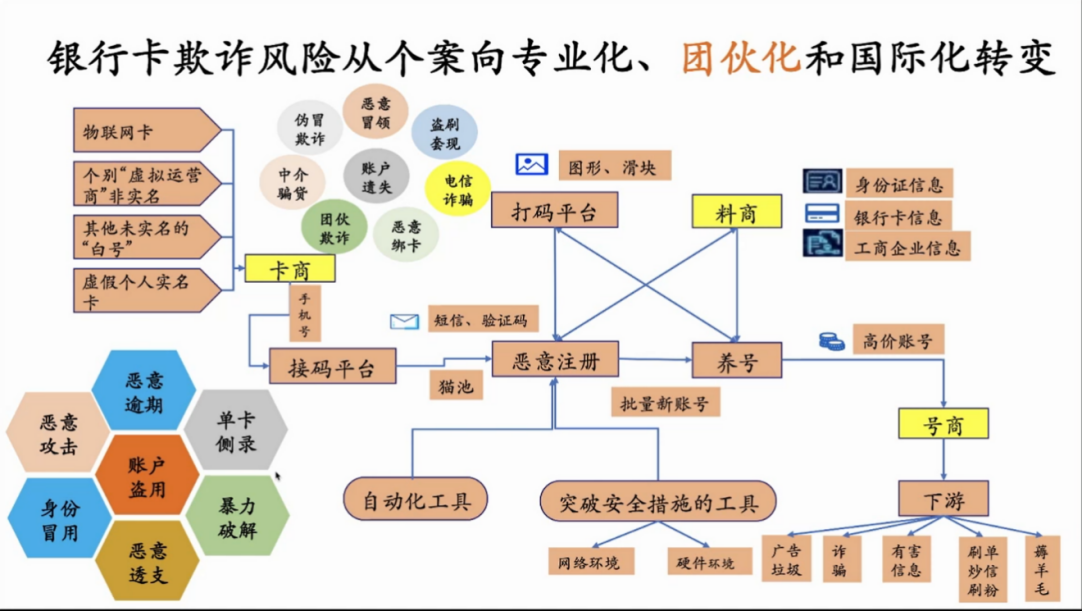
如上图所示,在这种银行卡电信欺诈当中,上、中、下游其实已经分化为卡商、料商和号商。下游号商做的事情,其实就是我们经常听说的薅羊毛、刷单、刷粉等有害信息的分发,包括这种诈骗过程当中使用的各种各样的技术都是为了逃避风控与监管。
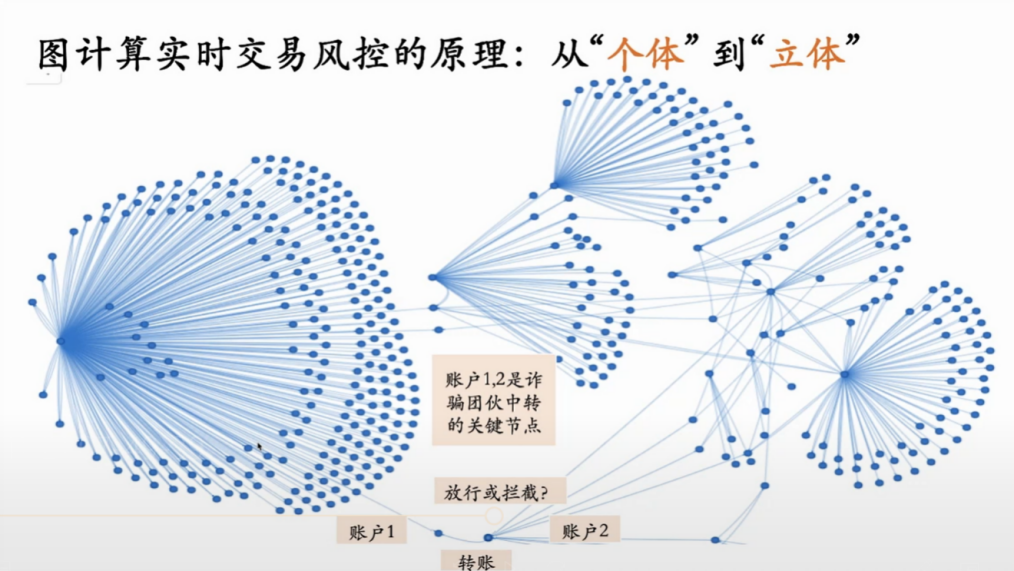
例如,两个账户之间做一些转账。如果仅看两个账户之间这条潜在的转账交易到底是实时放行还是拦截,行方很难决策。这并不取决于模型是怎么样。但如果我们能看到一个更大的picture——账户1和账户2的外围延展的交易网络,就能发现账户1和账户2是一个更大的诈骗网络当中关键的中转节点。此时,我们需要看到从单个账户到团伙网络,从单笔交易到整个交易的链条与网络。这就是图计算中的精髓。
打个比方,反欺诈规则由简到繁,可以看做是从点到线、到面、到体,有不同维度,对应的算力需求是逐级增加的。“点”即研究个体。所谓个体是只看一笔交易或一个账户。例如,多笔小额转账,每一笔的金额都接近5万(因为超过5万的转账就是非实时的)。
之前,九江市要求所有的商业银行在开设账户的时候,查看客户出具的居委会或村委会的居住证明。这种思路即试图在源头上,或者说从一个“点”的维度看有没有可能把风险堵住,尽量避免出现大规模上游传导下来的号商提供的卡号。因为每一笔单独看都是一些合理的需求,但整体构成一个网络之后却可能形成了规模效应,即个体会产生聚合效应。
如果从一条“线”的角度看,其实是资金的分散转出,即在下钻的过程当中,一个主账户会分出很多分账户。这种汇总的数据其实可以拆分到更细。从“点”到“线”,再到“面”分析明细数据会帮助我们建立更全局的观念。
账户之间的交易其实是一种复杂多层的嵌套关系。在这种嵌套关系网络当中,实际上有更多的信息值得挖掘,更多的行为可以被抽取。当然,最后到“体”的话,如果再加上时空或者其他维度的一些数据,就相当于是一种高维数据的计量。如,短时间内跨地区的多笔交易、短时间内多张卡在多个ATM按照某种接近限额的方式进行集中提现。
从点、线、面、体看,如果反欺诈的规则同步升级,对算力的需求是逐级增加的。这是传统数据库没有办法解决的,包括传统大数据的框架没办法很好地解决实时风控的原因也基于此。如果没有图查询语言,对多维数据间关联关系的查询、计算和表达会相当困难。
在关系型数据库中,涉及到多表的关联查询会造成计算的效率指数级下降,其背后的原因即笛卡尔乘积问题的存在。举例来说,两张表table-join实际造成的计算的复杂度其实是乘积的关系;如果是三张表就会变成N*N*N(假设每张表有N行);如果每张表是百万行、千万行甚至上亿行计算的量级。这种笛卡尔乘积计算的复杂度就变得非常可怕。例如三张表,每个都有1万行,10000×10000×10000,这已经是1万亿的复杂度。
在现有的计算体系框架内,我们是没有办法用传统数据库解决的。例如用关系型数据库与图数据库做一个深度穿透,从第2-5层,性能的差异其实是指数级上升的。例如,在1层的时候,两者可能并没有本质的区别;从2层开始会出现指数级的变化——16倍的差异、1000倍甚至几万倍的差异,直到用传统数据库做4-5层的穿透,通常不会完成这种复杂查询也不会返回任何结果。
数据库的发展历程也呈现出由“点”到“线”、到“面”、到“体”的一个大的趋势。从传统的关系型数据库,到大数据,再到快数据,最终到深数据(即图数据)的框架。在金融行业中,账户之间是复杂的、多层的(例如嵌套)关系,甚至,数据在高速地发生动态变化的时候,如何进行高效的关联关系计量(例如欺诈判定、归因分析)——这种挑战就是典型的深数据或者图数据的挑战。
在做实时交易风控时,六大维度是多方面的。内层,如时间、空间、环境、设备、关系、账户;外层,如行为轨迹、账户等级、关联交易,以及如何描述欺诈,如何做地址分析、终端分析等。由此看来,每一笔交易可能会需要上千条的规则来完成。这是非常复杂的,因为图计算关注的东西远远超越了单纯的一笔交易。
下面给大家分享几个具体的例子。
对信用卡或者贷款的申请,我们怎么判断是否存在欺诈问题?其实,两卡申请之间共享了大量的信息。如公司的信息、E-mail地址、设备ID、电话等,甚至包括介绍人的信息。那么,怎么做这种计算?一种办法是从某个账户出发去寻找是否存在一个4步的环路可以回到自身,即环路查询;另一种则更为高效,即查询两个贷款申请之间的邻居有多少共同的邻居。在数学中,第二种计算效率会更高。实际上,我们计算出来的结果也是这样的:在一个高并发的系统之内,查任意两个申请,完成的时间不超过5毫秒,完全可以做到以“纯实时、高并发”的方式完成。这是一个相对简单的例子,因为它聚焦得非常明确。
在数亿量级当中寻找到底有多少个涉嫌欺诈的电话号码。其中,被5个以上申请用过的电话号码可能会存在欺诈风险。这其实是面向全量数据的计算。如果采用传统的大数据框架至少需要几十分钟、甚至几个小时(即便不算数据动态加载的时间);但如果用实时图计算去做,在一秒钟左右即可完成。这就相当于将传统的、需要批量处理的工作实时化完成。
怎么在图上挖掘信贷?比如,信贷资金是否有违规流入楼市、股市或其他情况。我们可以从借款人的放款账户出发查询,经过多手的转账之后,最终的资金是否流入了房地产开发商的账户。如果用传统的大数据框架做这样的查询,复杂程度非常高,但利用图计算去做,一句话就可以做完。
一句话追踪资金流向的路径有如下两种:
一种是模板化的路径查询。即从放款的账户出发向外转账,转到另外一个账户可能会走3-5层,最终在抵达的账户将其过滤筛选,它是开发商的账户。这就是一个完整的查询语句,它表述了整个图上的查询。
另外一种是被称为K邻模板查询。K邻是图数据库比较典型的基础操作。它的逻辑是:从放款的账户出发,直接往外转出,最终要通过最短路径(或按照某种模板中定义的满足过滤规则的路径)抵达二手方的监管户,把它定义为别名,如定义为suspect,即认为有潜在的风险,最后返回的结果就是count,即可计算出到底有多少嫌疑的账户。
图计算里的QPS比传统数据库的QPS复杂得多。因为图上的查询是高维的、网络化的查询,远高于传统数据库的量级。同时,图计算解决了传统数据库的效率问题。每天进行上亿次的调用做实时风控,计算是确定的,拦截同样也可以做到非常准确。
例如,做实时的在线决策系统,每一笔交易的拦截,包括实时的构图、实时的规则的运行、风控引擎规则的运行,都要在20毫秒之内完成。实际上,在20毫秒之内,图计算可能已经跑了几十个QPS,因为几十个子查询完成了各个维度、规则的运行,最终构成了这笔交易是放行还是拦截的决策。
目前,日均监控的交易笔数都是千万-亿万笔,每一笔都会流经这样的系统。当然有一些交易系统并不能做出全自动的判断,依然会下发给最终的操作人员做二次分析。
图计算的另一个特点是因为它要解决的是复杂查询、深度查询,它的架构逻辑并不是去大规模的堆积机器,而是通过精简、高效的硬件架构来实现最大规模并发与算力的图计算系统。我们在某股份制银行的零售实时风控该系统,服务器的规模只有区区几台。比大量的依赖开源框架或分布式关系型数据库的系统动辄需要几十台上百台机器的计算效率要高得多。
图计算最终的目的是为了让银行能更好的满足业务迭代的诉求、提升客户体验,降低运营成本,提升社会效益等。
最后,我总结一下图计算的特点:首先,相比于其他数据库或者大数据框架,图计算的效率有指数级提升,甚至是成千上万倍的;其次是它的可解释性,即eXplainable AI (XAI),计算是非常确定的;第三,用更小的集群更高效地完成一件事情,甚至可以说,这本来就是一个碳中和的量化,如二氧化碳排放可以达到的70%-90%的大幅下降。
总而言之,在风控当中,所有的进攻方、欺诈方,无非是采用图的方式。从金融机构的角度来讲,做防御、反欺诈时要用的武器同样需要升级。如果是“魔高一尺”的话,那“道”就需高出一丈。而图计算是一个很好的工具,让我们可以在面对欺诈时的信心更加充足。
演讲稿整理:白峻赫
责任编辑:张语婷
来源:TGES 2021(第十七届)中国金融风险经理年度总论坛:
零售消费金融与风险管理(11月)




