
联系我们
如您对参会报名、网站使用、内容发布有任何疑问或改进意见,请随时与我们进行沟通!
客服企业微信

期待您的宝贵意见
袁先智博士 中山大学管理学院 广西大学经济学院与中国-东盟金融合作学院&成都数联铭品科技有限公司(BBD)
摘要:本文简要介绍了我们如何利用在大数据框架下基于人工智能的机器学习算法,通过刻画财务欺诈的指标和基于非结构化的公司治理结构的风险特征提取来建立解读公司治理结构(特别是公司财务欺诈行为)的风险预警体系。
财务舞弊是指企业的管理当局人为地操纵或篡改用于编制财务报表的底稿文件和会计凭证、不实披露或遗漏重要的财务信息、不正当的会计处理等行为;财务欺诈指企业管理当局有意地通过财务报告披露错误或具有误导性的信息的行为(参见文献[1-12]等讨论)。
美国注册会计师协会通过SAS No.99(见文献AICPA[3])指出欺诈是一个法律概念,审计师不应该做出公司是否存在欺诈的相关判断,但是审计师应该关注于财务报表重大错误陈述(或误导性陈述),因为财务报表中的重大错误陈述与财务欺诈是高度关联的;同时SAS No.99还指出有以下两类的错误陈述可以被认为是财务欺诈(见文献[1-12]中的讨论):
第一类:是人为操纵或篡改用于编制财务报表的底稿文件和会计凭证、不实披露或遗漏重要的财务信息、不正当的会计处理;
第二类:是通过侵吞或占用公司资产。
以上两种财务欺诈行为中第一类也是财务舞弊行为,而第二类则是由于公司在内控、审计等方面的缺陷以及内部的腐败等因素造成的。换句话说,财务舞弊与财务欺诈是难以分割又不完全相同的两个概念,对于公司来说财务舞弊行为往往与财务欺诈行为是共同存在的。
针对中国资本市场,常见舞弊类型有八类(见文献黄世忠等[12],袁先智[13-15]的讨论),它们主要有除常规的收入、成本费用舞弊(包含成本舞弊、费用舞弊)外,货币资金、投资收益、资产减值、营业外收支等科目也是逐渐成为管理层操纵业绩的对象。这几类财务舞弊表面上看似相互独立,实际上它们之间也是相互关联的。首先,收入舞弊与成本费用舞弊的目的都是为了提高公司的盈利表现,提高外界对公司的市值预期。其次,在操纵收入的过程中,为了满足勾稽关系,通常会对成本费用进行调整。最后,虚增的收入、费用和成本需要通过虚假的现金流加以掩饰。也正是这样,多种财务舞弊方式经常是共同出现的。
下面的表1是基于SAS财务标准 No.99 (参见文献[3-11])从压力、机会、借口三个部分来陈述财务欺诈需要考虑的范围和一般的(非结构化的)文字描述,因此,一个重要的工作是如何将其中的(非结构化)的文字描述归结成为针对非结构化数据的特征并进行刻画财务欺诈的特征筛选。
表1 针对财务欺诈基本定义的一般描述和考虑的范围
| 压力 | 机会 | 借口 |
|---|---|---|
|
1.金融稳定性或盈利能力受到经济、行业或者实际经营状况的影响: • 竞争激烈或利润下滑 • 行业环境快速变化 • 客户需求下滑 • 经营亏损 • 经营性现金流为负 • 快速增长或异常盈利 • 新的会计、政策、监管要求。
2.为了满足第三方的要求,管理层面临的较大的压力: • 盈利能力/趋势预期 • 额外的债务与股权融资需求 • 处在满足上市要求或偿还债务或其他债务契约的边界上 • 重大的未决交易可能带来财务不佳的预期。
3.管理层或董事由于个人财务状况产生的行为: • 存在重大利益关系 • 显著的绩效薪酬 • 个人债务担保。
4.为了达到董事或管理层设定的财务目标,管理层或公司经营人员承受了过大的压力。
|
1.所在行业提供了机会: • 异常的关联方交易 • 强大的财务实力与控制能力,使得能够制定有利的付款与收款合约或条件 • 需要估计的重大会计科目 • 重大的、异常且高度复杂的交易 • 跨国、跨化境、跨文化的重大业务 • 在避税天堂有着大量的银行账户。
2.无效的监督管理允许: • 少数人把控公司 • 董事会或审计委员会的监督不力。
3.组织结构复杂且不稳定: • 缺乏稳定的实控人或实控机构 • 过于复杂的组织结构 • 高级管理人员、律师及董事会的频繁变动。
4.内部控制缺陷: • 监督控制能力不足 • 无效的会计、内部审计、信息技术人员的频繁流动 • 无效的会计与信息系统。 |
1.董事会成员、管理层或员工的态度使得他们参与或对虚假报告进行证实是合理的: • 对道德规范无效的沟通、实施、支持或执行 • 非财务人员对会计政策和评估方法确定的过度参与 • 已知违反证券法或其他法律的历史 • 对维持或提高股价有过度的兴趣 • 激进且不真实的财务预期 • 信息的不及时披露 • 管理层的偷税漏税行为 • 管理层极力正式满足边界条件及不合理会计政策的合理性 • 与现任或前任审计师关系紧张 • 经常与现任或前任审计师发生纠纷 • 对审计师的不合理要求,如不合理的时间限制 • 对审计师的限制 • 与审计师打交道时过于专横。 |
在大数据框架下,为了提取能够提取具有甄别公司财务欺诈行为能力的特征因子, 一个首要的问题是我们需要解决坏样本不够的问题!那么如何解决这个问题呢?在大数据与仍智能技术发展的今天,这个问题其实可以通过基于人工智能的机器学习方法来构建需要的“坏样本”来推进这方面的工作, 即下面我们要介绍的使用吉布斯采样算法(Gibbs Sampling)(见文章[13-21]中的相关讨论)。
吉布斯采样(Gibbs Sampling)(见文献[16-17])是统计学中用于马尔可夫蒙特卡洛(MCMC)的一种算法,专门用于在难以直接采样时从某一多变量概率中近似抽取样本序列。该序列可用于近似联合分布、部分变量的边缘分布或计算积分(如某一变量的期望值,但如果某些变量已经为已知变量,就不需要采样)。吉布斯采样常用于统计推断(尤其是贝叶斯推断)之中,这是一种随机化算法,与最大期望算法等统计推断中的确定性算法相区别。另外,我们希望指出的是与其它MCMC算法一样,吉布斯采样是从马尔科夫链中抽取样本,它其实是Metropolis & Hastings算法的特例(见文献Geman and Geman[16]的相关讨论)。
大数据中的许多分类问题难以得到精确的答案,利用蒙特卡洛模拟框架下的吉布斯随机搜索算法,可在面对海量数据并在一定的误差容忍度的情形下,花费合理计算资源完成对特征问题的求解,从而得到一个近似解。下面我们将介绍如何基于吉布斯随机搜索算法来实现对刻画财务欺诈行为特征因子筛选框架和普通分析流程的建立(参见文献袁先智等[13-14])。
第一步:假定刻画财务欺诈行为的特征指标服从伯努利分布,对特征因子形成的特征空间进行初始化,并进行随机抽样,将特征根据系数是否为0进行分类: 不为0的记为1,为0的记为0,可得:
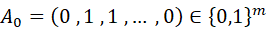
其中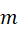 表示在初始化的特征空间中的特征个数,
表示在初始化的特征空间中的特征个数,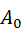 表示在初始化的特征空间中的一个子集。
表示在初始化的特征空间中的一个子集。
第二步:通过BIC (Bayesian Information Criterions)(见文献[16];另外也有AIC标准等可用,见文献[13-14]或[17])构建支持随机抽样计数的标准,并构建出特征的分布函数,得:
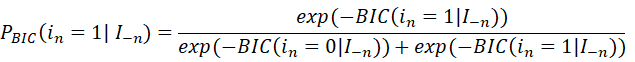
其中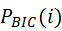 表示指标转移概率函数,
表示指标转移概率函数,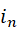 表示第n个特征,
表示第n个特征,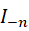 是除
是除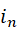 外的其他特征集合,在初始化的特征空间中的特征个数,
外的其他特征集合,在初始化的特征空间中的特征个数,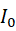 表示在初始化的特征空间中的一个子集,利用该公式来保证特征子集向拟合度更高的方向转移,使得最终刻画财务欺诈行为的特征指标的显著性得以显现。
表示在初始化的特征空间中的一个子集,利用该公式来保证特征子集向拟合度更高的方向转移,使得最终刻画财务欺诈行为的特征指标的显著性得以显现。
第三步:确定样本的抽样计数次数。确定抽样计算的次数是为了降低计算复杂度,让最终指标显著性的结果在可容忍误差范围内得以实现。此时,我们需要设定误差范围,为了保证提取的特征计算结果的显著性,样本量误差通常建议为不超过5%,其对应的公式如下:
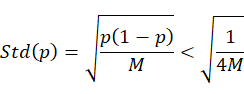
当以2个标准方差(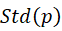 )(即, 2个Std(p))准则来控制模拟误差在5%以内,通过上面公式可求得抽样计数次数
)(即, 2个Std(p))准则来控制模拟误差在5%以内,通过上面公式可求得抽样计数次数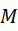 为400(次),这样该抽样计数的次数可以起到降低计算复杂度并保证特征显著性的效果。
为400(次),这样该抽样计数的次数可以起到降低计算复杂度并保证特征显著性的效果。
第四步:通过计算关联性的显著性进行特征因子的分类。即通过Odds Ratio(简记为,OR)指标对特征因子与基金绩效或期货价格变化的关联强度进行分类。
第五步:进行特征因子的甄别“好坏”的有效性测试。在进行不小于400次的吉布斯抽样计算,本文得到特征指标的组合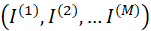 ,利用特征出现的次数与抽样总次数的比值,可求得特征出现的频率,进一步根据频率的高低分析特征对模型结果的影响。最终,通过受试者工作特征ROC (Receiver Operating Characteristic)下方面积AUC (Area Under the Curve ROC)(参见[13-14])作为模型的评价标准来衡量最终得到的特征指标的显著性(敏感性)。这样,我们就完成了构建最终趋势分析模型并进行对应的模型效果测试。根据第四步选择出的关联显著性大于某个设定水平的特征指标建立逻辑回归模型,分别在训练集合和预测集合中检验模型的效果。
,利用特征出现的次数与抽样总次数的比值,可求得特征出现的频率,进一步根据频率的高低分析特征对模型结果的影响。最终,通过受试者工作特征ROC (Receiver Operating Characteristic)下方面积AUC (Area Under the Curve ROC)(参见[13-14])作为模型的评价标准来衡量最终得到的特征指标的显著性(敏感性)。这样,我们就完成了构建最终趋势分析模型并进行对应的模型效果测试。根据第四步选择出的关联显著性大于某个设定水平的特征指标建立逻辑回归模型,分别在训练集合和预测集合中检验模型的效果。
就此,我们就完成了针对筛选刻画农户贫困的特征指标的分析流程的建立。
我们的咖啡馆(CAFÉ)评估框架中的“CAFÉ”代表的具体意思的解释如下:1)“C”代表针对公司基本的全息画像风险评估;2)“A”代表针对公司财务全息画像分析;3)“F”代表针对金融行为全息画像分析;和 4)“E”代表针对商务生态全息画像分析(参见文献[15])。
在此框架下,对应的评估流程由四步完成:第一步,初始特征构造,包括指标计算,数据预处理,即数据标准化和特征编码等;第二步,特征提取,包括基于吉布斯抽样(Gibbs Sampling)(和基于XGBoos算法,参见下面的介绍)的特征提取;第三步,模型构建,包含统计建模和机器学习建模;和第四步,模型整合与部署,包括各模块的整合模型、关键指标标准值、风险归因分析、概率评分转换等工作。
针对公司的“(财务)欺诈”行为进行甄别和预防的预警解决方案,可以从下面三个维度进行分析和处理, 即,第一,从公司本身的财务指标(公司的商务运营);第二,从公司的董监高出发的治理框架;和第三,从支持日程管理的内外审计管理和执行功能等方面(参见下图1):
图1 基于咖啡馆(CAFÉ)评估框架针对公司财务欺诈风险体系的建立
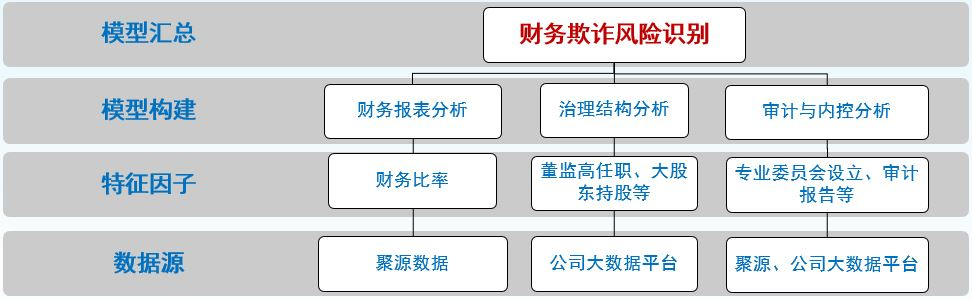
首先,利用在大数据框架下结合人工智能算法构建的咖啡馆(CAFÉ)风险评估体系为出发点,通过基于刻画企业财务欺诈风险特征的筛选框架(见袁先智等[13-14]中)所讨论的那样,通过对财务指标维度的风险特征提取,我们得到下面8个财务核心指标可作为针对公司财务质量评分模型的特征刻画,用于评估上市公司及发债企业的财务质量(见文献[15]),它们分别是:
指标1:扣非净利润增长率。扣非净利润是衡量公司盈利能力的重要指标,也是衡量公司经营状况的重要指标,如果长期扣非净利润表现不佳,则管理层面临较大的业绩压力,从而可能导致财务舞弊行为的发生。
指标2:在建工程增长率。在建工程是常见的会计操纵科目之一。可以通过增加在建工程金额或减少在建工程金额来调整公司的资产负债情况。
指标3:预付款项增长率。预付账款是常见的会计操纵科目之一。可以通过增加预付款或减少预付款来调整公司的资产负债情况。
指标4:利息费用(财务费用)/ 营业总收入。财务舞弊中,虚增的收入不是独立存在的,需要外部资金支撑对应的现金流,这部分资金必然带来额外的利息费用(财务费用),这是难以避免的。
指标5:投资净收益 / 营业总收入。投资收益是交易造假类舞弊的常见手段,与一般交易不同的是,投资收益可以通过关联方等渠道实现虚增收益,不需要对主营业务进行调整,对财务报表其他科目的影响相对较小,可以提高财务舞弊行为的隐蔽性。
指标6:其他收益 / 营业总收入。其他收益也是交易造假类舞弊的常见手段,不仅能起到与投资收益类似的作用,同时由于其他收益类型并不明确,给审计带来了更大的困难,进一步提高了财务舞弊行为的隐蔽性。
指标7:其他应收款(含利息和股利)/ 总资产。应收款是缓解虚增收入带来的现金流压力的有效途径,即可以通过增加应收款来实现不增加现金流入的情况下虚增收入。
指标8:长期借款 / 总资产。前文提到过,财务舞弊行为需要额外的现金流支撑,这一行为也可能是通过长期借款实现的。
然后,考虑公司大股东、管理层、董事会、监事会按照持股比例、担任的身份、内外的比例分类分析,利用CART分类方法和对应的 GXBoost算法(结合证据权重(WOE,即,Weight of Evidence)和信息价值(Ⅳ,即Information Value)信息量)来解释对评估对象可能会发生欺诈行为风险的影响,我们有下面针对公司治理结构好坏而刻画的非结构化特征评估指标(见文献[15]和文献[18-20]中的讨论),其核心是:公司股权结构是影响公司财务欺诈风险的重要因素,并通过可以通过下面四个特征从公司治理框架的角度来预警可能带来欺诈行为的表现:“第一,大股东和企业法人的持股比例在 5%到 50%之间;第二,大股东累计持股比例不超过 60%;第三,管理层的大股东持股比例小于 1%;第四,董事会中大股东比例不超过12%”。
这样,基于上面的二大类指标体系,再融合基于内部、外部审计相关数据的表现分析,我们就建立了比较全面的刻画公司财务欺诈行为的特征体系(参见上面图1的陈述)。
其实,在这个构建的过程中,我们会思考一个问题:为什么总存在有欺诈行为的公司?
针对这个问题,一个基本的事实是如果我们结合审计机构的业务情况、违规情况、合作情况,以及审计师的教育经历、工作经历等进行全面地梳理和分析,并利用审计表现指标的证据权重(WOE)进行分箱分析(参见文献[14-15]), 我们发现:1)公司审计委员会的人数、意见不一致等方面对公司的欺诈行为有相应的影响;2) 针对审计表现的 ROC 曲线测试呈现线性的表现也说明,一般来讲,外部审计只能发现公司有没有欺诈的行为,但形成不了针对公司财务欺诈行为的预防效应(因为如果外部审计工作能够形成预防效应,对应审计有效性测试的 ROC 曲线就应该是非线性(的凸函数)形式而非线性的状态);3)在对公司董事会人数与公司资质关系的研究中,我们也发现无论公司的评级如何,董事委员会人数只要在规定的合理范围(即,原则上董事成员数介于5到9人之间的范围),其人数多少不构成对公司经营好坏的特别影响。
另外,在业界实践中,我们会常常用遇到其它的机器学习方法也能支持金融场景在风险特征方面的提取,下面介绍一种比较流行基于XGBoost算法(也见Chen and Guestrin [18]中相关的讨论)的机器学习方法和对应的在刻画公司财务状况异常预警模型特征提取方面的应用。
在业界实践中,我们会常常用到其它的机器学习方法进行公司在金融场景风险特征的提取,下面介绍流行的基于极度梯度提升的集成学习“XGBoost”算法在筛选刻画公司财务状况异常状态的分析特征方面的应用案例和实践思路。
极度梯度提升的集成学习算法“XGBoost”(eXtreme Gradient Boosting) 因其具有较强的非线性信息识别能力和较高的预测精度成为机器学习的有利工具。我们在本节介绍通过引进XGBoost算法,结合上市公司中以制造业2018-2020年的125家因“财务状况异常”被划分为ST的公司主体和2116家非ST上市公司为样本,来建立针对上市公司财务预警模型的特征提取。
在我们的分析中,从企业的偿债能力、盈利能力、发展能力、营运能力及风险水平等7个方面确定了76个财务指标,并从企业的审计、内部治理、股权结构和创新能力4个方面确定了14个非财务指标建立财务预警指标作为初始特征指标,进行对应的描述上市公司财务预警的特征提取工作,得到的数据分析结果表明,与逻辑(Logistic)模型相比,我们使用的XGBoost方法对上市公司发生财务危机风险的预测能力更强和有效。
另外,借助“SHAP”(SHAPley Additive exPlanations)的解释框架(参见[18-20]中的讨论),可以帮助我们发现影响上市公司发生财务危机风险的重要因素和影响方式。本文建立的XGBoost财务预警模型不仅具备较高的预测可靠性而且还具有可解释性,这对上市公司财务危机风险识别和预警具有重要的意义(对应的详细结果,参见文献Li等[19]和Yang等[20]中的讨论)。
极度梯度提升的集成学习算法“XGBoost”(eXtreme Gradient Boosting)是一种集成学习模型,它基于GBDT模型进行了适当的拓展及改进,适用于多分类和回归问题。传统的GBDT模型在优化时只用到了一阶导数信息,而XGBoost模型对损失函数进行了二阶泰勒展开,同时用到了一阶、二阶导数的信息。此外,XGBoost模型在损失函数中加入了正则项,用于控制模型的复杂度,防止模型出现过拟合(见文献[18-19]及相关文献的讨论)。
我们的分析结果表明(见文献 Li等[19]的详细讨论)XGBoost算法与逻辑(Logistic)方法在构建公司财务预警模型的表现进行比较,GBoost算法对上市公司发生财务危机风险的预测能力更强,同时借助SHAP的解释框架,我们能够找出影响上市公司发生财务危机风险的重要因素和影响方式。
由于整个数据集中好样本和坏样本的比率约为19:1,我们首先采用SMOTE过采样方法(SMOTE,即 Synthetic Minority Over-Sampling Technique)处理不均衡数据(见文献石洪波等[21])将数据集中好、坏样本的比例调整为4:1。
基于待入模的数据集包含2616条数据和45列初步的特征变量(其中好、坏样本所占比例为4:1), 使用网格搜索利用Python3.7.6机器学习自带的Pipeline函数为模型寻找最优参数进行模型训练,使用训练好的模型对测试集样本的财务状况进行分类预测来获得最终分类结果。最后,利用Python程序,我们可以快速得到XGBoost算法和逻辑回归方法的下面四项评估指标系数(参见下面表2)。
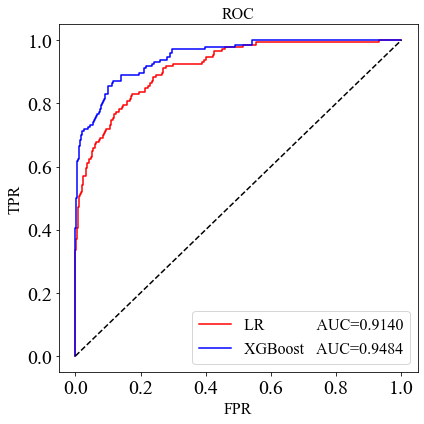
我们的结果(见下表2)表明,与逻辑(Logistic)模型相比,XGBoost方法除了对上市公司发生财务危机风险的预测能力更强外,结合SHAP的解释框架,也可以找出影响上市公司发生财务危机风险的重要因素和影响方式。
表2 XGBoost和逻辑回归两种方法的结果对比
| Accuracy | AUC | KS | Kappa | |
|---|---|---|---|---|
| XGBoost | 0.9248 | 0.9484 | 0.7560 | 0.7342 |
| 逻辑回归 | 0.8968 | 0.9140 | 0.6534 | 0.6309 |
同时对应XGBoost和逻辑回归两种方法的ROC曲线如下图2所示:
图 2 XGBoost方法和逻辑回归方法的ROC曲线对比
利用XGBoost方法并结合SHAP解释,我们有下面表3针对特征指标重要性的排列结论:
表3 XGBoost 算法基于SHAP框架提取的重要性特征排序
| XGBoost | SHAP |
|---|---|
| X85:上市公司是否违规 | X64:财务杠杆 |
| X47:托宾Q值 | X85:上市公司是否违规 |
| X45:市净率 | X42:市盈率 |
| X64:财务杠杆 | X49:现金股利保障倍数 |
| X49:现金股利保障倍数 | X45:市净率 |
| X42:市盈率 | X47:托宾Q值 |
| X67:每股收益 | X8:现金流利息到期债务保障倍数 |
| X52:总资产净利润率 | X41:总资产周转率 |
| X27:加权平均净资产收益率 | X86:研发人员数量占比 |
| X43:市销率 | X9:权益乘数 |
| X8:现金流利息到期债务保障倍数 | X43:市销率 |
| X28:基本每股收益 | X4:营运资金 |
| X66:综合杠杆 | X40:资本密集度 |
| X4:营运资金 | X2:保守速动比率 |
| X9:权益乘数 | X55:营业成本率 |
| X16:资本积累率 | X67:每股收益 |
| X86:研发人员数量占比 | X66:综合杠杆 |
| X17:总资产增长率 | X63:现金满足投资比率 |
| X71:每股未分配利润 | X1:速动比率 |
| X41:总资产周转率 | X16:资本积累率 |
汇总上面的讨论,我们有下面的基本结论:
XGBoost预警模型的预测效果明显优于逻辑(Logistic)方法,其准确度和泛化能力较强。
通过SHAP的解释框架,我们得出影响公司财务危机的主要特征指标变量有:“1)财务杠杆; 2)上市公司是否违规;3)市盈率;4)市净率;5)托宾Q值;6)现金股利保障倍数”。这些指标变量能够刻画公司的财务状况, 从而可以作为构建防范公司出现财务危机甚至破产现象的风险特征指标。
综上使述,XGBoost算法除了具备较高的预测可靠性外,并同时具有对应的可解释性,在刻画公司财务预警状况在特征提取的应用方面也是一个强有力的工具(另外,我们也指出支持本报告结论的分析和详细讨论,请参见文献[13-15,19-20]中的专门讨论)。
参考文献:
[1] 李清,任朝阳. 上市公司会计舞弊风险指数构建及预警研究[J]. 西安交通大学学报:社会科学版, 2016(36):36-44.
[2] Cressey, DR.. Other People's Money: A Study in the Social Psychology of Embezzlement.[J]. American Sociological Review, 1953, 19(3).
[3] AICPA. Statement of Auditing Standards No.99:Consideration of Fraud in a Financial Statement Audit[M].New York:AICPA 2002.
[4] Hopwood, WS., JJ. Leiner, GR. Young. Forensic Accounting and Fraud Examination (2nd edition)[M]. McGraw-Hill Education, 2011.
[5] Wells JT. Corporate Fraud Handbook: Prevention and Detection[M]. John Wiley & Sons, Inc., 2005.
[6] Dunn P. The Impact of Insider Power on Fraudulent Financial Reporting[J]. Journal of Management, 2004, 30(3):397-412.
[7] Sweeney SJT. Fraudulently Misstated Financial Statements and Insider Trading: An Empirical Analysis[J]. Accounting Review, 1998, 73(1):131-146.
[8] Beasley MS., JV. Carcello, DR.Hermanson et al. Fraudulent Financial Reporting: Consideration of Industry Traits and Corporate Governance Mechanisms[J]. Accounting Horizons, 2000, 14(4):441-454.
[9] Abbott LJ., Y.Park, S.Parker. The effects of audit committee activity and independence on corporate fraud[J]. Managerial Finance, 2000, 26(11):55-68.
[10] Abbott, LJ. etal. Audit Committees and Auditor Selection.[J]. Journal of Accountancy, 2001.
[11] Beneish M D. Detecting GAAP violation: Implications for assessing earnings management among firms with extreme financial performance[J]. Journal of accounting and public policy, 1997, 16(3): 271-309.
[12] 黄世忠, 叶钦华, 徐珊等. 2010~2019年中国上市公司财务舞弊分析[J]. 财会月刊, 2020(14).
[13] 袁先智,周云鹏,严诚幸等. 公司财务欺诈预警与风险特征筛选的新方法:基于人工智能算法[A]. 中国管理现代化研究会、复旦管理学奖励基金会.第十五届(2020)中国管理学年会论文集[C].中国管理现代化研究会,2020:16(第709到724页,www.cnki.com.cn).
[14] 袁先智,周云鹏,严诚幸等. 财务欺诈风险特征筛选框架的建立和应用[J/OL].中国管理科学, 2021, 05:1-12. https://doi.org/10.16381/j.cnki.issn1003-207x.2020.2201.
[15] 袁先智. 在金融科技框架下建立与国际通用的中国企业主体和债券的信用评级体系介绍. TGES-现代金融风险管理平台, (https://mp.weixin.qq.com/s/RwP6UTtk3hMF9gYkImqD7A), 中国人民大学, 2021年2月22日。
[16] Geman S, Geman D., 1984: “Stochastic Relaxation, Gibbs Distributions, and the Bayesian Restoration of Images”, IEEE Trans. Pattern Anal. Mach. Intell, 1984, 6.
[17] Qian G., CR.Rao, X. Sun et al. Boosting association rule mining in large datasets via Gibbs sampling[J]. Proceedings of the National Academy of Sciences, 2016:201604553.
[18] Chen, T and C Guestrin (2016). XGBoost: A scalable tree boosting system, KDD ’16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 2016, pp. 785–794, https://doi.org/10.1145/ 2939672.2939785.
[19] Hua Li, Yumeng Cao, Siwen Li, and Jianbin Zhao (2020). XGBoost model and its application to personal credit evaluation, IEEE Intelligent Systems, 35, 52–61.
[20] He Yang,Emma Li, Yi Fang Cai, Jiapei Li, and George X. Yuan. The extraction of early warning features for the predicting financial distress based on XGboost model and shap framework. International Journal of Financial Engineering Vol. 8(3) (2021) 2141004 (24 pages) (DOI: 10.1142/S2424786321410048).
[21] 石洪波,陈雨文,陈鑫. SMOTE 过采样及其改进算法研究综述[J]. CAAI Transactions on Intelligent Systems, 2019, 14(6): 1073-1083.
(责任编辑:王琦)
来源:TGES 2021年高级线下研讨会:零售小微、普惠金融与风险管理(7月)




