
联系我们
如您对参会报名、网站使用、内容发布有任何疑问或改进意见,请随时与我们进行沟通!
客服企业微信

期待您的宝贵意见
一、压力测试概述
压力测试很大一部分是监管要求,从巴塞尔II开始提到了在第一支柱、第二支柱当中有八大风险。去年银保监会有九大风险,业界的一些专家也提到了9+X风险,类型非常之多。对于金融机构而言,从外部来看是外监管,但如果换一个角度来看,它和内部的增效也是息息相关的。风险的类型非常多样,压力测试中的量化怎么去做、用什么样的算法、模型、算力,可以使整个压测的过程变得更加smooth(流畅)和准确,这是我们追求的目标。
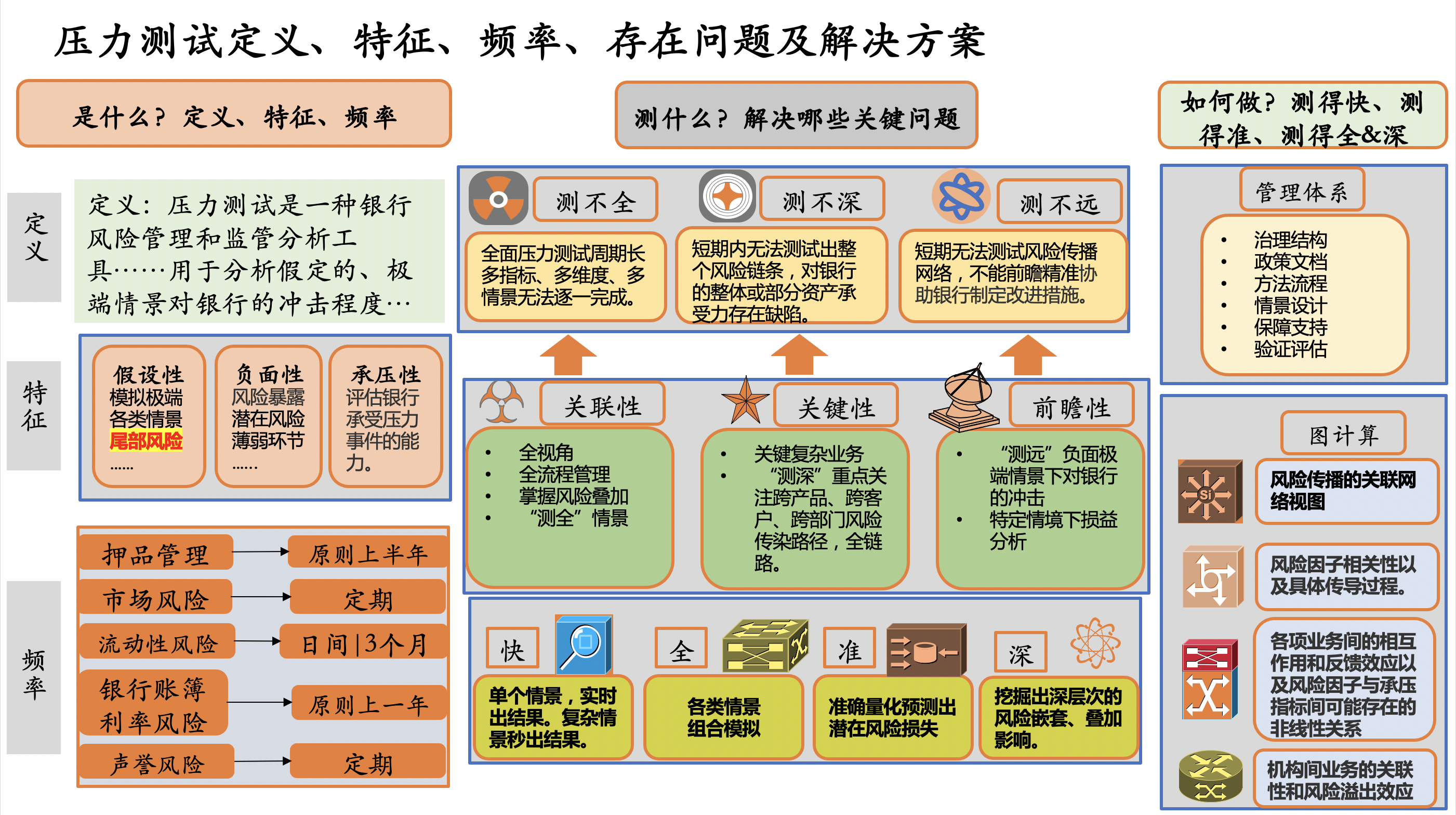
图 1压力测试的定义与解决的关键问题
压力测试分为三个部分:是什么(定义-特征-频率)、测什么(解决什么问题)、如何实现。以压测频率为例,市场风险、流动性风险、声誉风险等都有一些定期的压测的需求。以流动性风险为例,按照监管的需求,LCR是日报,NSFR是每三个月一次,欧洲的监管机构和金融该机构甚至会做到日间的计量,从技术架构的角度上看,几乎是完全不同的架构才可以去应对以LCR为例的每月、每周、每日、日间甚至是纯实时计量需求。
压测有假设性、负面性、承压性的特征,像尾部风险指发生概率小,但是有可能会造成较大损失的极端风险。通常说银行基于历史数据和统计关系建立的计量模型,有的时候很难有效识别并反映尾部风险。压测可以测试极端的事件和场景对于金融风险的影响,来弥补一些模型存在的不足,比如银行构建VaR模型来度量市场风险,但它可能低估了从未发生的尾部事件造成的影响和损失,压测的方法可以对VaR模型做出补充和修正。
压测能解决哪些问题?我们主要关注关联性、关键性和前瞻性。当然我们希望能做到快、全、准、深,但现在很多模型,包括匹配的算力,测不全,也测得不够深,比如短期之内没有办法度量出完整的、全部的风险链条,以及银行整体或者部分资产的承受力、存在的缺陷;测得不远,比如测试风险传播的网络、路径,就没有办法很好的、前瞻性的去精准协助银行制定改善措施。我们提出的观点跟做出的实践就是用图计算的方式,把风险传播看作关联的网络,我们从网络视图的角度上看风险因子之间的相关性以及具体的传导过程,图计算的过程应该是白盒化、可解释的,尤其是对于业务人员,跟第二代人工智能,就是机器学习、深度学习的方法是很不一样的。
二、承压指标的分类
我们前面讲到很多所谓的机器智能,如果人类不能很好解释,就不是很白盒化、可解释的过程,意义较为模糊。这里有点、线、面、体的概念(如下图所示),如果把承压指标分成4大类的话,对于算力的挑战是逐级增加的。比如点其实是典型的个体的、离散的指标,比如存款余额,运算实际上是聚合运算;从下往上看,账户是有多层分类的,存款有大额存单协议存款等结构性存款,再往上看,有活期、定期这种零售、对公不同的模式,单独看它是典型的离散个体的聚合,这方面的计算用传统数据库是没有任何问题的。
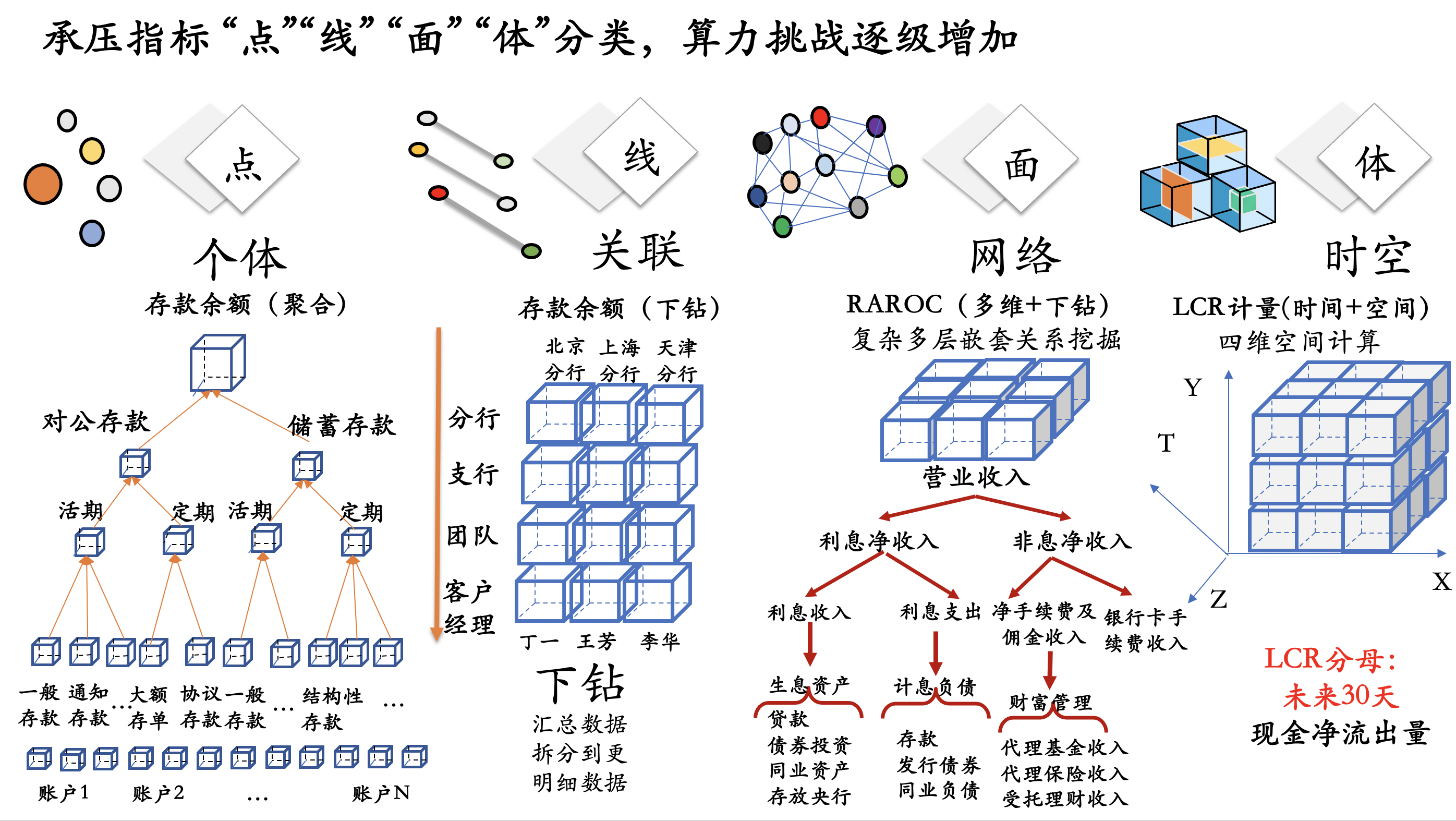
图 2算力需求的逐级递增(点-线-面-体)
下面接着看怎么做现状的关联性计算。依然以存款余额为例,如果从分行、客群、客户经理的角度,从团队的角度去看,这种下钻其实是一方面做汇总,另外一方面拆分成另外一个维度,按照某条线去看,计算的复杂度要比点的聚合计算更高。
再看网络化的计算,这就涉及到复杂多层的嵌套关系,比如银行当中RAROC指标是一种典型的多维和下钻,营业收入拆分成利息净收入、非息净收入,再往下去看,有生息资产、计息负债、财富管理等,网络化的计算复杂度又显著高于线性计算。
最后如果去看体的计算,其实是典型的高维计算,是多维数据之间的关联。前面的数据可能还会加上时间、空间和其他的维度,比如流动性覆盖率涉及的其实是全行几乎所有数据,从零售到对公到同业等几乎全部的业务,它的计算其实是典型的多维数据之间的关联计算,也涉及到聚合、多维、下钻、归因分析等等。
三、传统数据库面临的问题
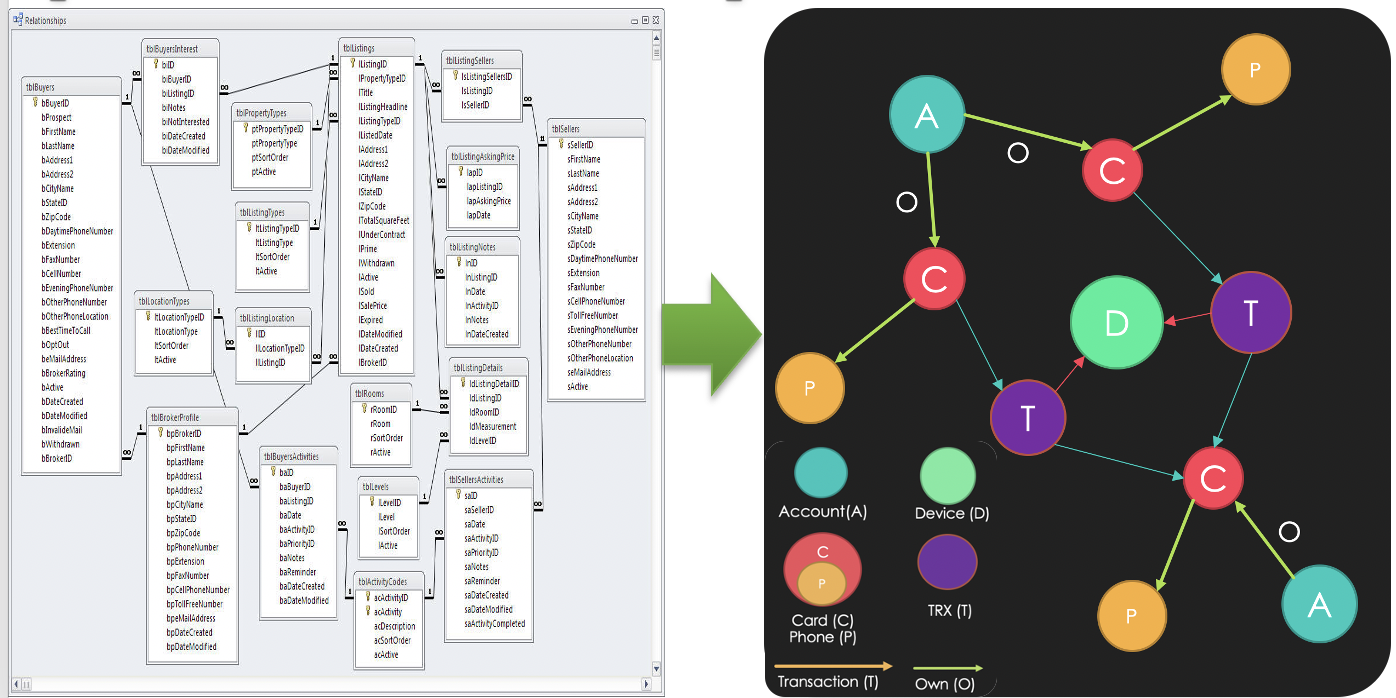
图 3从关系型数据库(SQL)到图数据库(GQL)
从技术角度讲,在传统数据库架构或者大数据的框架当中,以典型的表结构为例,描述一个典型的交易场景中可能涉及的表有很多张(如上图所示左侧的19张表)。同样的这些表,如果去构造交易图谱?我们会有两类元数据:点和边,点代表实体,例如账户、机构、用户等,边代表交易、隶属、拥有等关系。这些点与边会形成一张相互关联网络,或者叫图谱数据集。
传统的二维表有笛卡尔积的问题。例如有三张表,每张表只有两行,但是如果做表的连接(table-join),计算量因为扫表(笛卡尔乘积)就变成了2*2*2=8行,如果是稍微大一点的三张表做关联,每张表1万行,那就变成了天文级的万亿的计算量。
但如果从图的视角看,其实就是3万个实体或者3万个点边所构成的非常小的图,理论上讲在图论的视角来看,不应该造成计算的压力。我们做了一些实验,用典型的MySQL和图数据库来对比:深度为2的时候,两者之间并没有特别本质的区别,性能大概有几倍到十几倍的差异,但是深度到3的时候就已经到了上千倍,如果是深度为4的话就有4000倍以上的差异。这是一张非常小的图,大概有50万的点,几百万的边。如果是5层,关系型数据库就已经没有办法完成计算了,但图数据库依然几乎是纯实时的完成,如果画一张图来表达,可以看到关系数据库的执行时间和图数据库计算时间,随着深度的增加,呈现出指数级的性能落差。
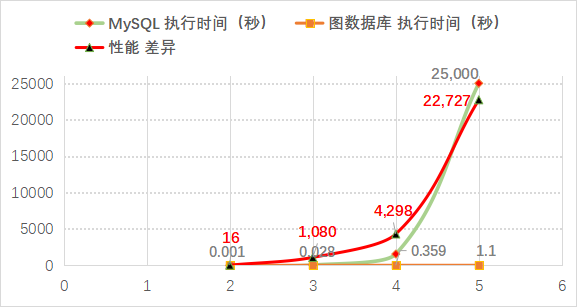
图 4两种数据库性能落差巨大
我们回顾过去40年整个数据处理技术的发展历史,再结合点、线、面、体的承压指标的计量,从80年代开始的关系型数据库,包括后面出现的数仓,以及过去十几年开始出现的大数据、快数据,是一个典型的发展趋势,从SQL到NoSQL。但今天看到越来越多,特别是在金融行业中,对于算力的需求,因为出现了多元的、多维的数据,要去进行深度的关联分析,这种趋势其实是从关系型数据到大数据再到快数据,最终走向的是图数据,即Deep Data与Graph Data。整个的计算的模式也是从点到线到面到体的大的发展趋势。
四、图计算的压力测试实践
以恒大事件为例,它本质危机是流动性危机。在这种情景下,对于几百家、上千家关联的银行机构冲击的压力测试应该怎么去做?从恒大出发,包括债券持有人、投资人、理财购买者以及关联公司、供应链网络中怎么看上下游、员工、购房者等等,如果一层层用图的思维延展开,一是链条效应,网络化传播的效果,还有就是所谓系统性风险,指风险的外溢性。我们看它的传导路径、传染的客群里是不是存在一些风险传播的超级节点,这都是压测中会去关注的一些点。
又例如给某证券交易所做的压测场景,要达到的效果是可以从任何集团、某某系去查看关联公司的股权穿透,例如从一个发行人出发,到另外十几万他关注的个体公司的自然人之间全部的最短路径,查询的深度可能是从6层到10层,如果考虑全量的,以中国为例,全量工商图谱的量级在10亿上,审核人员之前是没有办法用传统数据库和AP数仓类计算框架来完成实时操作的,计算量非常巨大,而现在我们可以做到两秒钟内完成从任意一个实体、发行人出发,到十几万家公司和自然人之间的全部的最短路径。这个计算是通过实时图计算来完成的。
在交易网络中也有类似的效果。例如以某集团为圆心,以它的风险传播路径为半径,把风险影响到的客群识别出来,比如有几千家关联公司,几十万员工,更大数量的供应商,以及数以百万的购房者等等。在情景分析、敏感性分析当中,会涉及到轻度、中度、重度的各种组合,以及一些承压指标,如RWA、不良率、违约率等,包括风险的Exposure(敞口、暴露),用图的方式其实是构建了风险传导机制的全景图。
数据是根本,如果能拿到相应的数据,并且数据间具有一定连通性,剩下的问题就是构图了。构图也是需要一些经验和智慧的,怎么从传统的二维表构造成高维关联的风险传导的图谱,是很关键的一步。
五、图计算解决压力测试的难点和问题
用图计算的优势去解决压测当中的一些痛点和难点,我们大概梳理出6大优势:
一是计算实时性,我们把传统意义上的几乎所有风险的计量压测,从T+1/T+2,甚至更久时间,做到了T+0或者纯实时。
二是在这个过程中,涉及到关联性识别,要通过深度穿透和挖掘,包括动态剪枝(过滤)来模拟真实的、可能的风险的传播。
三是复杂多层嵌套,即形成风险传播的路径,按照某种模板传播,或者按照更为暴力的最短路径的传播。
四是多压测情景。在压测当中,例如流动性风险管理当中,监管要求只有15种场景,但实际上从内增效的角度讲,银行机构可能会需要更多种的压测,如果把LCR构造成一棵树,它有144个子项,如果做乘积关系,压测的场景是无穷无尽的,而图计算可以提供更多情景下的灵活与高效实现。
五是3D可视化,压测如果能配合可视化的全景3D视图,效果会更好、更直观。
六是集群更小,低运维。我们所用的其实是更小规模的集群来完成复杂类型查询的计算,这比大规模AP类型的集群更高效、TCO更低。
最后总结起来,我们认为图计算相比于传统技术,甚至是实时图计算相比于非实时图计算,整个效率的提升,是指数级的,甚至到上万倍的提升。图计算另外一个很好的优点就是白盒化,我也一直坚定的认为,模型如果没有很好的可解释性,准确性的基础是存在一定的问题的。另外就是碳中和,这也是大势所趋,充分的释放底层硬件的能力,是需要在软件层面上获得的,并不是说堆上一堆机器,我们就天然的获得了算力。很多看似庞大的集群中的平均每台机器或实例的处理效率、效能其实很糟糕。金融场景中,特别是压力测试,涉及到很多长链条复杂查询与计算,不加甄别的去照搬互联网的短链条、高频但是简单查询(秒杀)模式下所用的各种AP类型的数仓、云架构,往往不能很好解决我们的问题。
撰稿人:梁丹辉
责任编辑:傅泽天
来源:TGES2021(第十七届)中国金融风险经理年度总论坛:风险分析、量化和压力测试(一)(12月)




