
联系我们
如您对参会报名、网站使用、内容发布有任何疑问或改进意见,请随时与我们进行沟通!
客服企业微信

期待您的宝贵意见
缪维民 新加坡CriAT公司联合创始人和首席执行官
本次分享的是《前瞻性量化信用分析在债券市场的应用》。这里的量化信用分析,是指 Credit Analytics,即基于数据和模型对信用风险进行系统性地计算分析。在债券市场的应用中,量化信用分析的核心是预测未来,因此具有前瞻性(Forward-looking)是极其重要的。
简单介绍下我所在的公司。CriAT是新加坡国立大学的衍生公司,源于成立于2009年的Credit Research Initiative (信用研究行动计划,简称 CRI )项目。CriAT专注于深度信用分析 (DeepCredit® Analytics),提供一系列基于前沿技术的分析数据和工具,以及企业级解决方案,助力风险和投资管理方面的数智化转型。
在探讨量化信用分析之前,我们先来看看传统的基本面分析和信用评级。
在基本面分析中,分析师详细考察企业的财务报表,评估其财务风险、经营风险、外部支援等。在此基础上,他们就企业的信用是否在改善、恶化或稳定形成意见,并有可能进一步分析债券价格是否被高估或者低估。基本面分析有如下的优势:优势一,能密切和深入地监控企业行为;优势二,能识别潜在的“事件风险”,例如杠杆收购、股权回购等;优势三,具有分析师的前瞻性。但是基本面分析也存在明显的劣势:劣势一,通常来自单个或几个分析师的意见;劣势二,断断续续,不完整的覆盖,不同分析师往往不具有一致性;劣势三,无法永远对市场动向和事件及时反应;劣势四,分析结果难以量化、难以聚合;劣势五,优秀的分析师很贵。不过值得强调的是,虽然量化分析不断发展,迄今为止,基本面分析仍然是无可替代的。
信用评级是由评级机构根据公开和私有信息评定的信用等级。我这里仅讨论国际三大评级机构。对于中资美元债,标普(S&P)、穆迪(Moody’s)、惠誉(Fitch)的评级通常是可靠的,特别是债券发行时的首次评级。图1展示了穆迪对于中资美元债的评级数量和违约分布,可以看到违约企业的评级基本处于BB-以下,可见穆迪评级和违约的对应关系是基本可靠的。不过信用评级的劣势也很明显,例如评级反应相对迟钝、信用恶化时可能存在卖方评级偏差、评级变化往往滞后于市场等。
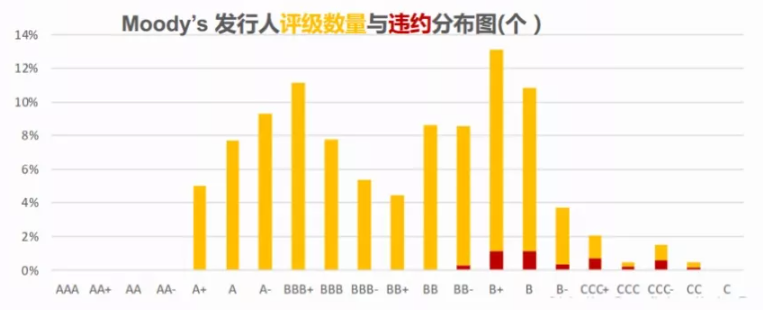
图1 穆迪发行人评级数量与违约分布图(个)
债券市场业务对信用分析有着更高的要求。信用分析是一体两面,从风险视角是是风险评估,重点是关注违约;从投资视角是风险定价,重点是关注利差;如图2所示。谈到量化信用分析,离不开几个基础测度,如违约率(Probability of Default,PD)、违约损失率(Loss Given Default ,LGD)、违约风险敞口(Exposure at Default,EAD)等。对于债券的风险和投资管理,这些基础测度的颗粒度和精确度,对分析结果的品质有着关键的影响。目前用于传统信贷业务的信用分析,在准确性和及时性上无法满足债券业务的需求。
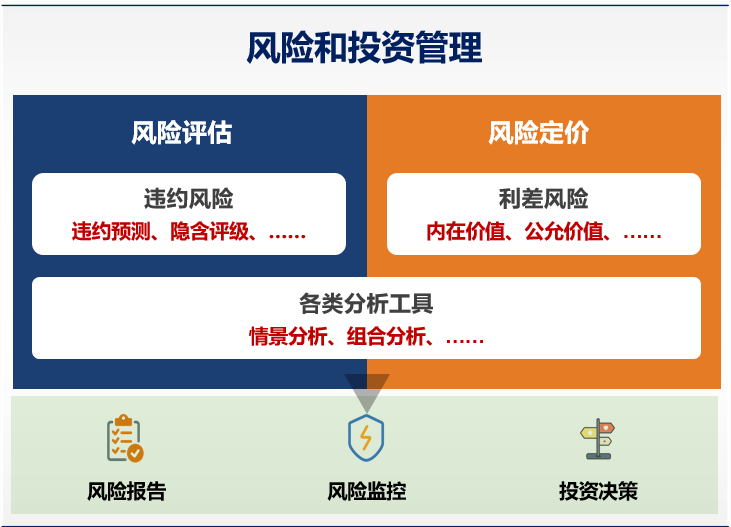
图2 信用分析的一体两面
1、违约概率 - 信用利差
风险评估和风险定价,通过违约概率和信用利差联结,如图3所示。违约率反应了一家企业在未来某一段时间内违约的可能性;结合债券的未来现金流和违约回收率,可以进一步计算分析出该支债券的内在价值和公允价值。因此可见,违约率是风险评估和风险定价的核心基础。债券市场的应用场景对违约预测有更高的要求。首先,违约率必须是一个量化的数值,其次,违约率必须要有期限结构。
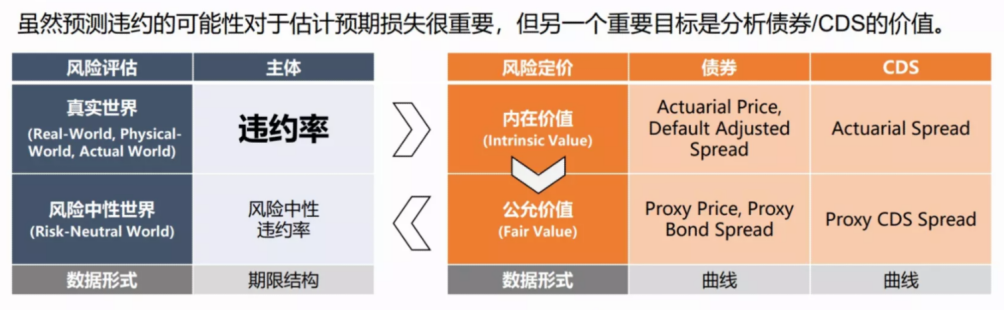
图3 从违约概率到信用利差
2、常见的违约率模型
通常而言,违约率模型分为三大类:
第一类是结构模型(Structural Model),其基本原理是资不抵债,即企业的股权价值视为以资产为标的、以债务为执行价格的看涨期权来刻画企业资产价值,并假设资不抵债这一违约激发机制来度量企业信用风险。
第二类模型是市场隐含模型(Market-Implied Model),其基本原理是基于市场价格反推,基于风险中性和有效市场假设,即债券/CDS的市场价格体现的风险溢价全部是对未来违约损失的补偿。
第三类模型是简约模型(Reduced-Form Model),通常是回归预测,基于全量历史数据,刻画违约事件发生与诸多经济、市场和企业的相关信息的相关关系。
我们来看下三类模型的适用性。结构模型因为基于股市信息,一方面受限于股市的有效性,在中国等新兴市场效果不佳;另一方面仅适用于上市公司,而中国上市公司仅占债券发行人的四分之一。市场隐含模型,基于债券价格反推,难以剥离风险溢价反应真实违约风险,而且从严格意义上说是一种基于市场共识的推算,而并非违约预测。
简约模型,经历了几十年间从静态模型发展到动态模型,具体表现为从1968年的第一代判别分析模型(Z-score 评分模型)产生评分,到1980年开始的第二代定性响应模型(逻辑回归模型)产生概率,再到2000年之后的第三代强度模型/久期模型(即期强度模型、远期强度模型)产生概率期限结构。简约模型需要全量历史数据建模,对于数据处理和建模技术要求比较高,特别是中国债市违约数据不多,如何构建在实战中稳健有效的模型需要高超的建模水平。
3、如何形成更好的前瞻违约预测?
前瞻违约预测的“前瞻”来自两点,一是前瞻信息,二是前瞻模型。
股市信息和债市信息都属于前瞻信息,其中包含了市场对企业未来的认知。股市信息能够通结构模型形成股市映射风险(如违约距离),债市信息能够通过市场隐含模型形成债市映射风险。因此把这两种前瞻信息转换成前瞻风险因子,与企业财务数据和宏观与行业数据相结合,并辅以一些特色因子如财务报表的延期等,应用于违约预测中,是很自然的选择。
前瞻模型,笼统地说就是指动态模型,模型中考量违约的时间动态结构,比如强度模型中假设违约是双随机泊松过程的首次跳跃。前瞻模型确保了多期违约预测的一致性和稳健性。
我们推荐以“前瞻信息+前瞻模型”的方式构建违约预测。基于以上分析,该方式其实是将上文提到的三类模型以混合(Hybrid)方式进行有机结合,从而达成更好的前瞻预测。当然,风险因子的构建和选择,模型参数的估计和校准,每一件都不是容易的事情,这里我们就不详细阐述了。
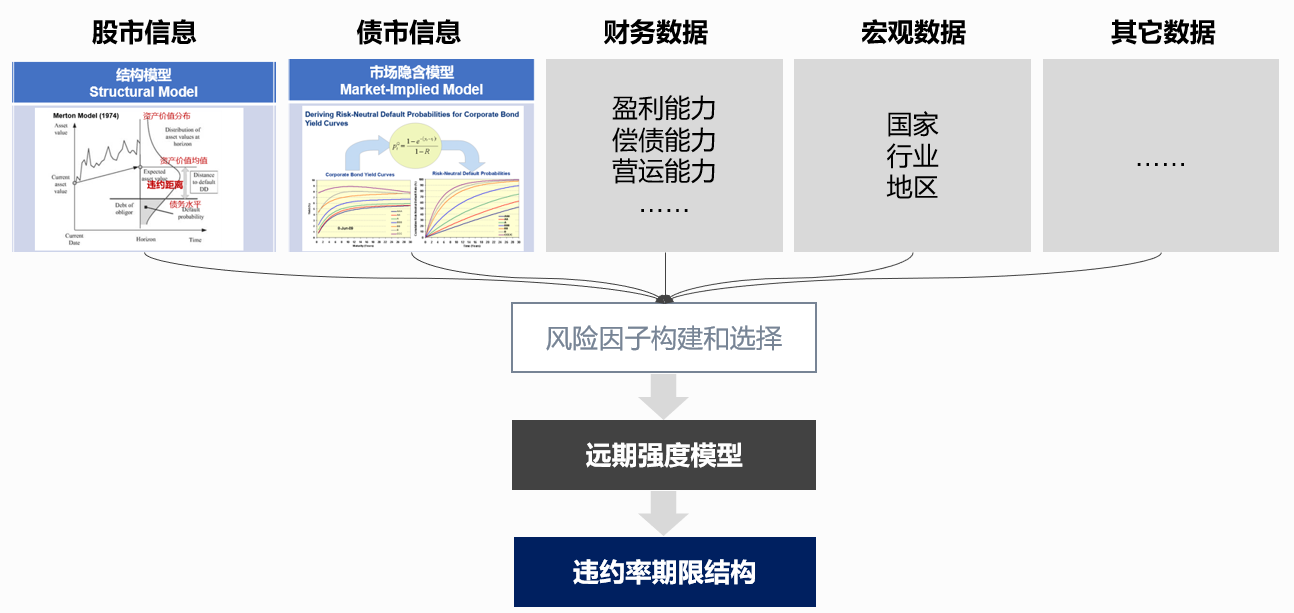
图4 “前瞻信息+前瞻模型”形成前瞻违约预测
4、各风险因子在违约预测中的表现
我相信大家很关注各风险因子对违约预测的重要性。这里以CriAT的产业债模型为例,分享我们基于全量数据的检验结果。CriAT的产业债模型的风险因子包括主体股市映射风险(可以理解为类似穆迪分析KMV-EDF)、主体债市映射风险(可以理解为类似中证/中债的市场隐含违约率)、各类财务因子,如营运能力(资产周转率)、盈利能力(资产收益率)和偿债能力(资本负债率)等,以及宏观与行业和其它特色因子。
图5展示了基于2010年到2021年的全量数据的检验结果,其中第3列的单因子一年期AR值(Accuracy Ratio)反映了第2列中的各风险因子对企业未来一年信用好坏的区分能力。AR值越高代表该风险因子对信用好坏的区分能力越强。可以看到,主体债市映射风险的AR值约为70%,是所有风险因子中最高的。这非常符合我们的真实感受,就是债券价格和企业违约风险有高度相关性。而主体股市映射风险的AR值约为40%,这也符合大家的真实感受,就是KMV-EDF针对中国的表现一般。我们通过风险因子筛选形成产业债模型的“最优”组合后,AR值达到了82.3%。AR值的增加难度是呈指数级的,这表明各类风险因子相结合的重要性。
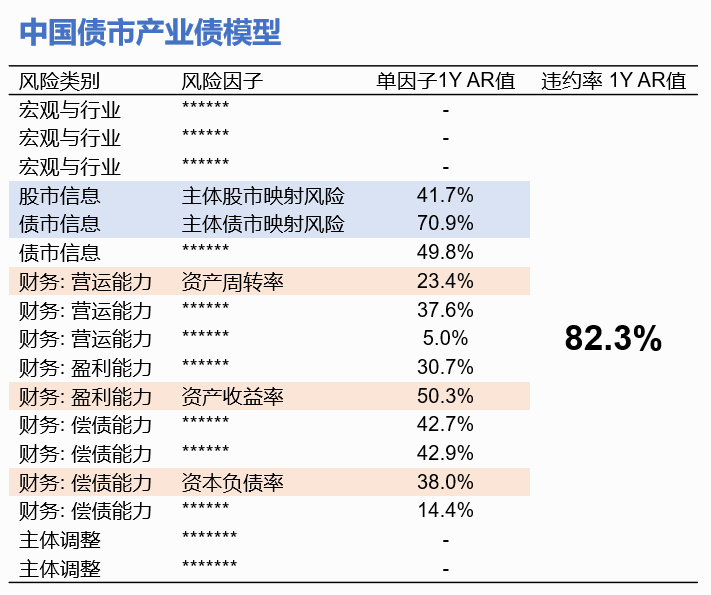
图5 中国债市产业债模型
我们同时也注意到各风险因子对违约率的贡献度随着时段的变化而不同。图6展示了2010年迄今、2014年迄今、2018年迄今,各风险因子类别贡献度的变化。可以看到,偿债能力(深灰色)一直是最为突出的指标,宏观与行业(蓝色)的影响近几年来越来越大,而市场信息(黄色)、运营能力(灰色)、盈利能力(浅灰色)在差不多量级。
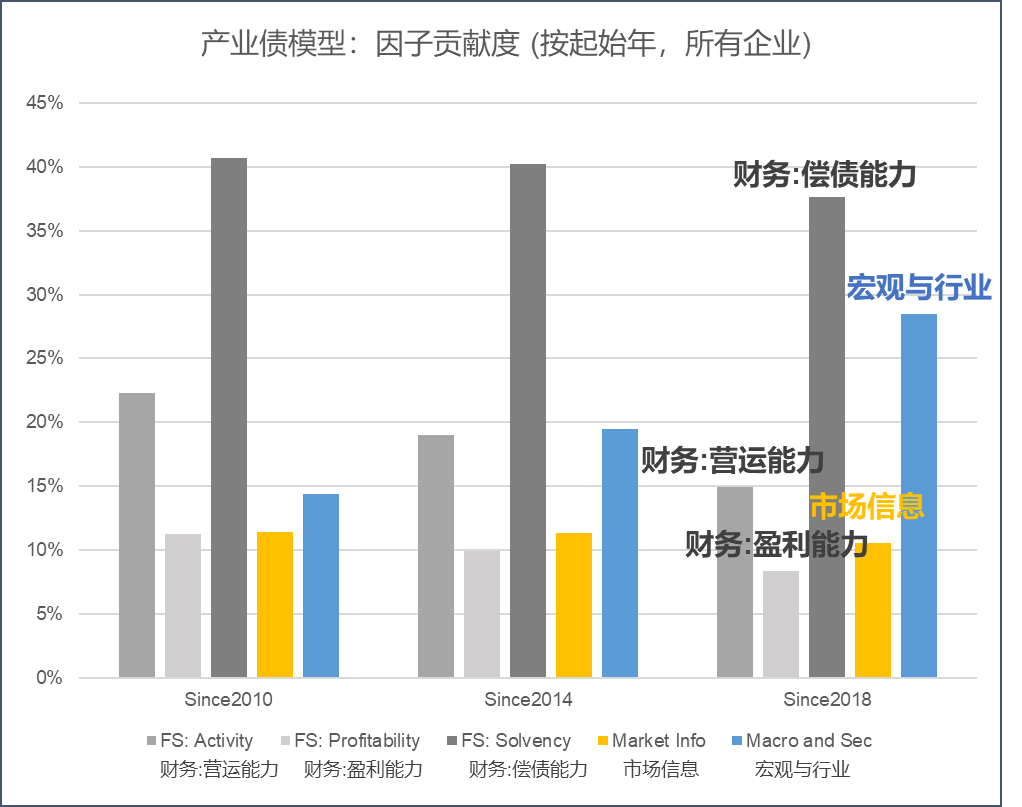
图6 各风险因子在违约预测中的表现
图6从对所有企业的分析,如果换到仅所有违约企业,情况又有所不同。如图7所示,从左至右表示从违约前24个月到违约前1个月各风险因子类别贡献度,可以明显地看到市场信息(黄色)随着违约临近贡献度越来越大,这很容易理解,因为市场在不断的做出反应。不过值得注意的是,企业个体的偿债能力、盈利能力仍会占到相当大的比重,这隐性对应了信用风险恶化时各风险类别1+1>2的联合效应。
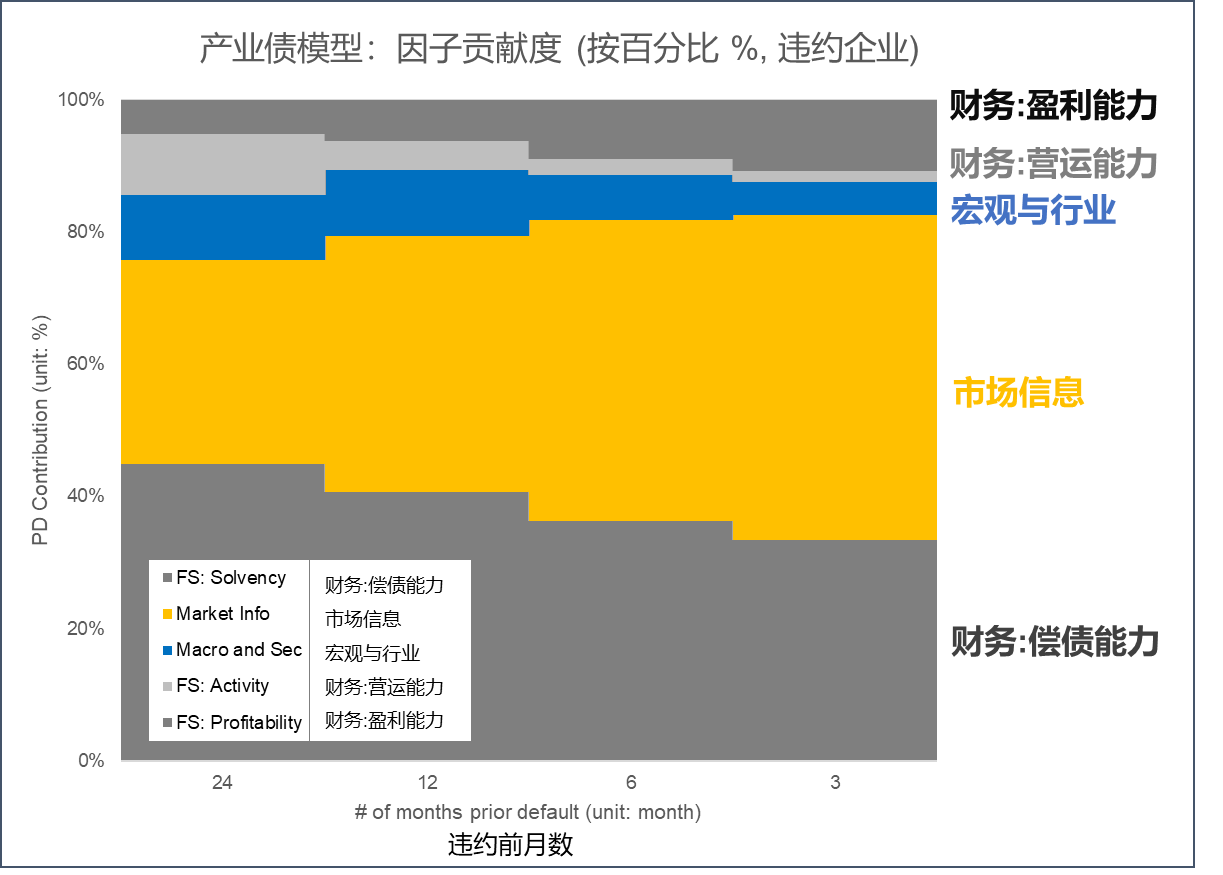
图7 各风险因子在违约预测中的表现
5、探讨:新闻舆情?
毋庸置疑,新闻舆情和信用风险有很高的关联性。但是违约预测模型是否需要引入新闻舆情信息是值得探讨的。新闻舆情,有些是对未来信用状况的领先信息,有些是对于已发生信用事件的滞后反应。新闻舆情在解释上具有高度复杂性,这对数据结构化本身也带来了巨大的难度,比如CEO更换究竟是负面信息还是正面信息,比如通过融资进行业务拓展有可能对于权益市场是正面的,但对于债券市场是负面的。考虑到股市和债市信息中已经对新闻舆情信息有很大的吸收,因此我个人建议在违约预测中不要轻易使用新闻舆情,而不妨作为分析违约率变化的一个解释参考。
6、违约率应用:隐含评级和信用预警
隐含评级(PD implied Rating, PDiR)是违约预测的副产品,基于违约率划定阈值,映射到21级评级分类。阈值的产生可以根据机构需求,比如以标普、穆迪、惠誉在中资美元债市场上的信用评级为标尺。
信用预警是违约预测的直接应用,违约预测的前瞻性确保了信用预警的准确和及时。违约预警可以根据业务需求,基于隐含评级处于投资级/投机级,或者所划阈值的查全率/查准率、虚警率/漏警率形成。当然也可以进一步依据机构需求,形成更为进阶的信用预警。
1、违约概率-信用利差
从属于风险测度的违约概率,到属于投资测度的信用利差,是非常重要的一环,这形成了风险和投资一致的量化语言。不同的机构有不同的投资目的和风格,持有或交易,配置或博利,但是对债券利差分析都有着共同的需求。基于违约率期限结构,结合适当的违约回收率假设,我们能够从风险的视角,将债券利差进行分层分析,如图8所示,其中多少是违约风险溢价,多少是流动性和其他风险溢价,从而产生债券的内在价值和公允价值,进行相对价值分析和绝对价值分析。
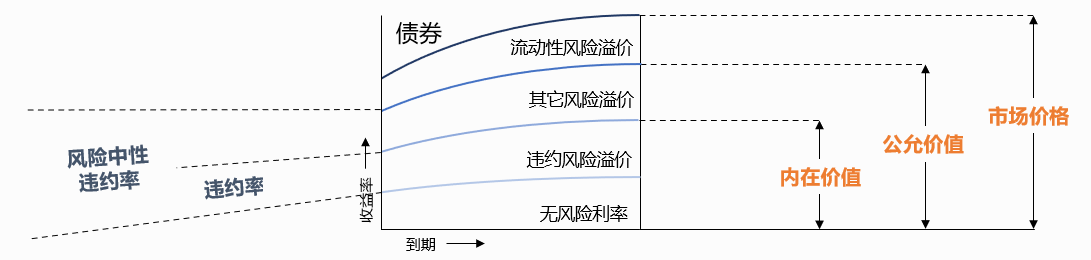
图8 内在价值,公允价值,市场价格
2、债券内在价值 - 违约调整后利差
违约调整后利差(Default-Adjusted Spread)是基于目前市场价格,用违约调整后现金流(Default-Adjusted Cashflow)取代名义现金流,计算考虑违约风险后的债券真实利差,其中违约调整后现金流的计算需要高质量的违约率期限结构。违约调整后利差反应了债券的内在价值。
举例绝对价值分析。比如一只债券,利差是45.9基点,而违约调整后利差为 -0.2基点,这意味着该债券的违约风险已抵消了所有利差所得。也就是说这只债券如果持有到期,从期望值的角度,是亏损的。
再举例相对价值分析。如图9所示,三支BB+到BB-评级的债券,利差分别是A:88基点、B:85基点、C:91基点,但是债券发行人的违约率相差较大,对应的违约调整后利差分别是A:86基点、B:38基点、C:-12基点。违约调整后利差越低,意味着债券利差里面隐含更多地信用风险。通过对比分析,我们自然会相对优选A债券。
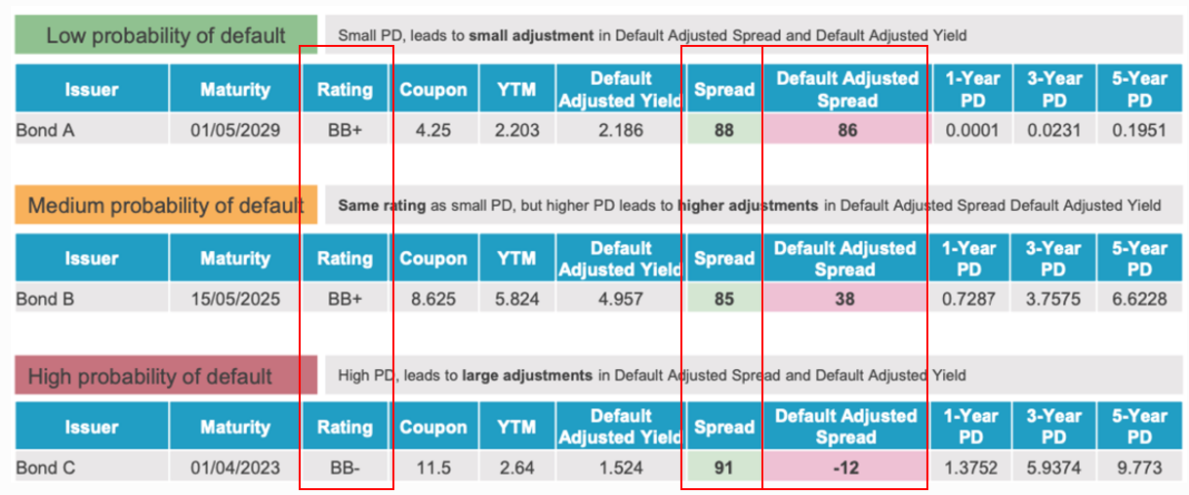
图9 违约调整后利差:相对价值分析
国内部分从业人员更习惯价格,违约调整后利差也可以转化成为精算价格。精算价格因为仅仅考虑了违约风险,而没有考虑其它风险溢价,所以通常高于观察到的市场价格。但是当企业的违约概率显著高于债券市场参与者共识时,精算价格就有可能低于市场价格,这明确表明债券价值在市场中被高估了。
3、CDS公允价值:拟 CDS利差
CDS是欧美等成熟金融市场中重要的金融工具,而我国CDS市场仍处于发展初期,CDS报价覆盖面窄,流动相差。我们得到企业主体的违约率期限结构后,可以先依据CDS合约定价机制计算CDS中信用风险的部分,然后通过构建大数据风险溢价模型形成拟CDS利差 (Proxy CDS Spread)。在风险溢价建模的过程中,为了克服数据不足的问题,可以使用多种技术手段,如借用环球市场的利差驱动因子,采用CFETS-SHCH-GTJA高等级CDS指数为基准等,我们这里略过细节。拟CDS利差可以 用于CS01计算、CVA计算、CDS定价等各种应用场景。
我们举例看下实际效果。中国银行的CDS是目前中国流动性最好的之一。图10展现了拟CDS 利差(深红色)与IHS Markit的 CDS利差(蓝灰色)的比较,可以看到整体趋势贴合度较高。同时也可以观察到两个利差的量级上有显著差别,如图上最后一个点2021年6月对应的值,拟CDS利差是19基点,而IHS Markit CDS利差是46基点。两者之间有系统性差别,这是可以预期的,通过分析帮助我们进一步得到关于中国CDS市场的深入见解。
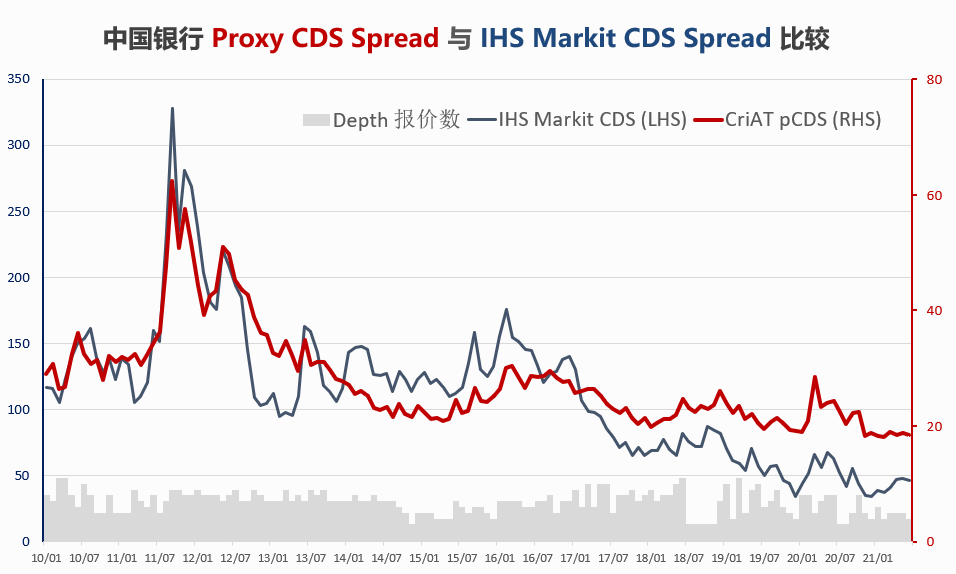
图10 中国银行 拟CDS利差与 IHS Markit CDS 利差的比较
最后进行一个总结。有时候会从国内听到一个观点,认为我国的金融市场和发达国家金融市场不一样,时间累积不够,成熟度不够,还有很多政策性因素的影响,因此量化信用分析在中国没有效果,是不适用的。我个人并不认同这个观点。我们想一想发达金融市场的信用风险模型,能叫的出名字也没几个,而且都是许多年来和市场共同成长,迭代改进从而形成共识价值。国内市场打破刚性兑付没几年,需求才刚刚开始,人才才刚刚聚集,这是我们的劣势,但我认为也是我们的优势。目前发达金融市场流行的信用风险模型大部分都是基于几十年前的分析技术,而近十多年来,数据维度的延伸,分析技术的进步,计算能力的飞跃,让我们有机会蛙跳式地形成在量化信用分析上的领先。当然,这个过程艰巨且漫长,这需要金融机构和专业厂商一起长期共同努力。
责任编辑:张语婷
来源:2022年TGES前沿讲座:第七期 债券投资与风险管理




